Routing protocols and architectures/Software-based packet filtering
Software which is able to parse fields in packets finds place, running on integrated circuits or microprocessors, in a variety of applications:
- switch: learning algorithms are based on frame source and destination MAC addresses, and frame forwarding is based on destination MAC addresses;
- router: packet forwarding is based on source and destination IP addresses;
- firewall: if a rule based on packet fields is matched, it throws the associated filtering action (e.g. drop);
- NAT: it converts IP addresses between private and public and TCP/UDP ports for every packet in transit;
- URL filter: it blocks HTTP traffic from/to URLs of websites in a black list;
- protocol stack: the operating system delivers the packet to the proper network-layer stack (e.g. IPv4 or IPv6), then the packet goes to the proper transport-layer stack (e.g. TCP or UDP), at last based on the quintuple identifying the session the packet is made available to the application through the right socket;
- packet capture: applications for traffic capture (e.g. Wireshark, tcpdump) can set a filter to reduce the amount of captured packets.
Typical architecture of a packet filtering system
edit
- Kernel-level components
- network tap: it intercepts packets from the network card and delivers them to one or more[1] filtering stacks;
- packet filter: it allows only packets satisfying the filter specified by the capture application to pass, increasing the capture efficiency: unwanted packets are immediately discarded, and a smaller number of packets is copied into the kernel buffer;
- kernel buffer: it stores packets before they are delivered to the user level;
- kernel-level API: it provides the user level with the primitives, typically ioctl system calls, needed to access underlying layers.
- User-level components
- user buffer: it stores packets into the address space of the user application;
- user-level library (e.g. libpcap, WinPcap): it exports functions which are mapped with the primitives provided by the kernel-level API, and provides a high-level compiler to create on the fly the pseudo-assembler code to be injected into the packet filter.
Main packet filtering systems
editCSPF
editCMU/Stanford Packet Filter (CSPF, 1987) was the first packet filter, and was implemented in parallel with the other protocol stacks.
It introduced some key improvements:
- implementation at kernel level: processing is faster because the cost for context switches between kernel space and user space is avoided, although it is easier to corrupt the entire system;
- packet batching: the kernel buffer does not delivers immediately a packet arrived at the application, but waits for a number to be stored and then copies them all together into the user buffer to reduce the number of context switches;
- virtual machine: filters are no longer hard-coded, but the user-level code can instantiate at run time a piece of code in pseudo-assembler language specifying the filtering operations to determine if the packet can pass or must be discarded, and a virtual machine in the packet filter, made up in practice of a switch case over all the possible instructions, emulates a processor which interprets that code for each packet in transit.
BPF/libpcap
editBerkeley Packet Filter (BPF, 1992) was the first serious implementation of a packet filter, adopted historically by BSD systems and still used today coupled with the libpcap library in user space.
- Architecture
- network tap: it is integrated in the NIC driver, and can be called by explicit calls to capture components;
- kernel buffer: it is split into two separate memory areas, so that kernel-level and user-level processes can work independently (the first one writes while the second one is reading) without the need for synchronization exploiting two CPU cores in parallel:
- the store buffer is the area where the kernel-level process writes into;
- the hold buffer is the area where the user-level process reads from.
NPF/WinPcap
editThe WinPcap library (1998), initially developed at the Politecnico di Torino, can be considered as a porting for Windows of the entire BPF/libpcap architecture.
- Architecture
- Netgroup Packet Filter (NPF): it is the kernel-level component and includes:
- network tap: it sits on top of the NIC driver, registering itself as a new network-layer protocol next to stardard protocols (such as IPv4, IPv6);
- packet filter: the virtual machine is a just in time (JIT) compiler: instead of interpreting the code, it translates it into x86-processor-native instructions;
- kernel buffer: it is implemented as a circular buffer: kernel-level and user-level processes write to the same memory area, and the kernel-level process overwrites the data already read by the user-level process → it optimizes the space where to store packets, but:
- if the user-level process is too slow in reading data, the kernel-level process may overwrite data not yet read (cache pollution) → synchronization between the two processes is needed: the writing process needs to periodically inspect a shared variable containing the current read position;
- the memory area is shared among the CPU cores → the circular buffer is less CPU efficient;
- Packet.dll: it exports at the user level functions, independent of the operating system, which are mapped with the primitives provided by the kernel-level API;
- Wpcap.dll: it is the dynamic-link library with which the application directly interacts:
- it offers to the programmer high-level library functions needed to access underlying layers (e.g. pcap_open_live(), pcap_setfilter(), pcap_next_ex()/pcap_loop());
- it includes the compiler which, given a user-defined filter (e.g. string ip), creates the pseudo-assembler code (e.g. "if field 'EtherType' is equal to 0x800 return true") to be injected into the packet filter for the JIT compiler;
- it implements the user buffer.
- New features
- statistics mode: it records statistical data in the kernel without any context switch;
- packet injection: it sends packets through the network interface;
- remote capture: it activates a remote server which captures packets and delivers them locally.
Performance optimizations
edit- Evolution of performance optimization techniques.
-
 Traditional architecture.
Traditional architecture. -
 Architecture with shared buffer.
Architecture with shared buffer. -
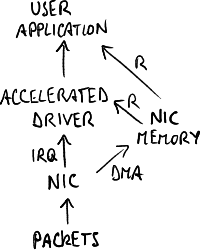 Architecture with accelerated driver.
Architecture with accelerated driver.



In recent years network traffic has grown faster than computer performance (memory, CPU). Packet processing performance can be improved in various ways:
- increase capture performance: improve the capacity of delivering data to software;
- create smarter analysis components: only the most interesting data are delivered to software (e.g. URL for a URL filter);
- optimize architecture: try to exploit application characteristics to improve performance.
- Profiling data (WinPcap 3.0, 64-byte-long packets)
- [49.02%] NIC driver and operating system: when entering the NIC, the packet takes a lot of time just to arrive at the capture stack:
- the NIC transfers the packet into its kernel memory area via DMA (this does not use the CPU);
- the NIC throws an \textbf{interrupt} (IRQ) to the NIC driver, stopping the currently running program;
- the NIC driver copies the packet from the NIC memory into a kernel memory area of the operating system (this uses the CPU);
- the NIC driver invokes the operating system giving it the control;
- the operating system calls the various registered protocol stacks, including the capture driver;
- [17.70%] tap processing: operations performed by the capture driver at the beginning of the capture stack (e.g. receiving packets, setting interrupts);
- [8.53%] timestamping: the packet is associated its timestamp;
- [3.45%] packet filter: filter costs are proportionally low thanks to the JIT compiler;
- double copy into buffers: the more packets are big, the more copy costs increase:
- [9.48%] kernel buffer copy: the packet is copied from the operating system memory to the kernel buffer;
- [11.50%] user buffer copy: the packet is copied from the kernel buffer to the user buffer;
- [0.32%] context switch: it has an insignificant cost thanks to packet batching.
Interrupts
editIn all operating systems, at a certain input rate the percentage of packets arriving at the capture application not only does no longer increase, but drastically decreases because of livelock: interrupts are so frequent that the operating system has no time for reading packets from the NIC memory and copying them into the kernel buffer in order to deliver them to the application → the system is alive and is doing some work, but is not doing some useful work.
Several solutions exist to cut down interrupt costs:
- interrupt mitigation (hardware-based): an interrupt is triggered only when a certain number of packet has been received (a timeout avoids starvation if the minimum threshold has not been achieved within a certain time);
- interrupt batching (software-based): when an interrupt arrives, the operating system serves the arrived packet and then works in polling mode: it immediately serves the following packets arrived in the meanwhile, until there are no more packets and the interrupt can be enabled back on the card;
- device polling (e.g. BSD [Luigi Rizzo]): the operating system does no longer wait for an interrupt, but autonomously checks by an infinite loop the NIC memory → since a CPU core is perennially busy in the infinite loop, this solution is suitable when really high performance is needed.
Timestamping
editTwo solutions exist to optimize timestamping:
- approximate timestamp: the actual time is read just sometimes, and the timestamp is based on the number of clock cycles elapsed since the last read → the timestamp depends on the processor clock rate, and processors are getting greater and greater clock rates;
- hardware timestamp: the timestamp is directly implemented in the network card → packets arrive at software already having their timestamps.
User buffer copy
editThe kernel memory area where there is the kernel buffer is mapped to user space (e.g. via nmap()) → the copy from the kernel buffer to the user buffer is no longer needed: the application can read the packet straight from the shared buffer.
- Implementation
This solution has been adopted in nCap by Luca Deri.
- Issues
- security: the application accesses kernel memory areas → it may damage the system;
- addressing: the kernel buffer is seen through two different addressing spaces: the addresses used in kernel space are different from the addresses used in user space;
- synchronization: the application and the operating system need to work on shared variables (e.g. data read and write positions).
Kernel buffer copy
editThe operating system is not made to support large network traffic, but has been engineered to run user applications with limited memory consumption. Before arriving at the capture stack, each packet is stored into a memory area of the operating system which is dynamically allocated as a linked list of small buffers (mbuf in BSD and skbuf in Linux) → costs for mini-buffer allocation and freeing is too onerous with respect to a large, statically allocated buffer where to store packets of any size.
Capture-dedicated cards are no longer seen by the operating system, but use accelerated drivers incorporated into the capture stack: the NIC copies the packet into its kernel memory area, and the application reads straight from that memory area without the intermediation of the operating system.
- Implementations
This solution is adopted in netmap by Luigi Rizzo and DNA by Luca Deri.
- Issues
- applications: the other protocol stacks (e.g. TCP/IP stack) disappeared → the machine is completely dedicated to capture;
- operating system: an intrusive change to the operating system is required;
- NIC: the accelerated driver is strongly tied to the NIC → another NIC model can not be used;
- performance: the bottleneck remains the bandwidth of the PCI bus;
- timestamp: it is not precise because of delays due to software.
Context switch
editProcessing is moved to kernel space, avoiding the context switch to user space.
- Implementation
This solution has been adopted in Intel Data Plane Development Kit (DPDK), with the purpose of making network devices programmable via software on Intel hardware.
- Issues
- packet batching: the context switch cost is ridiculous thanks to packet batching;
- debug: it is easier in user space;
- security: the whole application works with kernel memory;
- programming: it is more difficult to write code in kernel space.
Smart NICs
editProcessing is performed directly by the NIC (e.g. Endace):
- hardware processing: it avoids the bottleneck of the PCI bus, limiting data displacement (even though the performance improvement is limited);
- timestamp precision: there is no delay due to software and it is based on GPS → these NICs are suitable for captures over geographically wide networks.
Parallelization in user space
editFFPF proposed an architecture which tries to exploit the application characteristics to go faster, by increasing parallelism in user space: the capture application is multi-thread and runs on multi-core CPUs.
Hardware can help parallelization: the NIC can register itself to the operating system with multiple adapters, and each of them is a distinct logical queue from which packets exit depending on their classification, performed by hardware filters, based on their fields (e.g. MAC addresses, IP addresses, TCP/UDP ports) → multiple pieces of software can read from distinct logical queues in parallel.
- Applications
- receive side scaling (RSS): the classification is based on the session identifier (quintuple) → all the packets belonging to the same session will go to the same queue → load on web servers can be balanced:
 B8. Content Delivery Network#Server load balancing;
B8. Content Delivery Network#Server load balancing; - virtualization: each virtual machine (VM) on a server has a different MAC address → packets will directly enter the right VM without being touched by the operating system (hypervisor): C3. Introduction to Software-Defined Networks#Network Function Virtualization.
References
edit- ↑ Each capture application has its own filtering stack, but all of them share the same network tap.