Routing protocols and architectures/Routing algorithms
| Routing algorithms presented in the following assume they work on a network based on routing by network address. |
A routing algorithm is a process of collaborative type in charge of deciding, in every intermediate node, the directions which must be used to reach destinations:
- it determines the destinations reachable by each node:
- it generates information about the reachability of local networks: the router informs its neighbor routers that the local network exists and it is reachable through it;
- it receives information about the reachability of remote networks: a neighbor router informs the router that the remote network exists and it is reachable through it;
- it propagates information about the reachability of remote networks: the router informs the other neighbor routers that the remote network exists and it is reachable through it;
- it computes optimal paths (next hops), in a cooperative way with the other nodes, according to certain criteria:
- a metric has to be established: a path may be the best one based on a metric but not based on another metric;
- criteria must be coherent among all the nodes in the network to avoid loops, black holes, etc.;
- the algorithm must operate automatically to avoid human errors in manual configuration and to favor scalability;
- it stores local information in the routing table of each node: a routing algorithm is not required to know the entire topology of the network, but it is only interested in building the correct routing table.
- Characteristics of an ideal routing algorithm
- simple to implement: less bugs, easy to understand, etc.;
- lightweight to execute: routers should spend as less resources as possible in running the algorithm because they have limited CPU and memory;
- optimal: the computed paths should be optimal according to the chosen metrics;
- stable: it should switch to another path just when there is a topology or a cost change to avoid route flapping, that is the frequent change of preferred routes with consequent excess of transient periods;
- fair: it should not favour any particular node or path;
- robust: it should be able to automatically adapt to topology or cost changes:
- fault detection: it should not rely on external components to detect a fault (e.g. a fault can not be detected at the physical layer if it occurs beyond a hub);
- auto-stabilization: in case of variations in the network it should converge to a solution without any external intervention (e.g. explicit manual configuration);
- byzantine robustness: it should recognize and isolate a neighbor node which is sending fake information, due to a fault or a malicious attack.
Internet does not implement byzantine robustness, but it is based on confidence → faults and malicious behaviours require human intervention.
- Classification of routing algorithms
- non-adaptive algorithms (static): they take decisions independently of how the network is:
- static routing (or fixed directory routing)
- random walk
- flooding, selective flooding
- adaptive algorithms (dynamic): they learn information about the network to better take decisions:
- centralized routing
- isolated routing: hot potato, backward learning
- distributed routing: Distance Vector, Link State
- hierarchical algorithms: they allow routing algorithms to scale up on wide infrastructures.
Metric
editA metric is the measure of how good a path is, obtained by transforming a physical quantity (e.g. distance, transmission speed), or a combination of them, in numerical form (cost), in order to choose the least-cost path as the best path.
A best metric does not exist for all the kinds of traffic: for example bandwidth is suitable for file-transfer traffic, while transmission delay is suitable for real-time traffic. The choice of the metric can be determined from the 'Type of Service' (TOS) field in the IP packet.
- Issues
- (non-)optimization: the primary task of routers is to forward users' traffic, not to spend time in computing paths → it is better to prefer solutions which, even if they are not fully optimized, do not compromise the primary functionality of the network and do not manifest problems which can be perceived by the end user:
- complexity: the more criteria are combined, the more complex the algorithm becomes and the more computational resources at run-time it requires;
- stability: a metric based on the available bandwidth on the link is too unstable, because it depends on the instantaneous traffic load which is very variable in time, and may lead to route flapping;
- inconsistency: metrics adopted by nodes in the network must be coherent (for every packet) to avoid the risk of loops, that is packet 'bouncing' between two routers using different conflicting metrics.
Transients
editModern routing algorithms are always 'active': they exchange service messages all the time to detect faults autonomously. However, they do not change the routing table unless a status change is detected:
- topology changes: link fault, addition of a new destination;
- cost changes: for example a 100-Mbps link goes up to 1 Gbps.
Status changes result in transient phases: all the nodes in a distributed system can not be updated at the same time, because a variation is propagated throughout the network at a finite speed → during the transient, status information in the network may not be coherent: some nodes already have new information (e.g. the router detecting the fault), while other ones still have old information.
Not all status changes have the same impact on data traffic:
- positive status changes: the effect of the transient is limited because the network may just work temporarily in a sub-optimal condition:
- a path gets a better cost: some packets may keep following the old path now become less convenient;
- a new destination is added: the destination may appear unreachable due to black holes along the path towards it;
- negative status changes: the effect of the transient manifests itself more severely to the user because it interferes also with the traffic that should not be affected by the fault:
- a link fault occurs: not all routers have learnt that the old path is no longer available → the packet may start `bouncing' back and forth saturating the alternative link (routing loop);
- a path worsens its cost: not all routers have learnt that the old path is no longer convenient → analogous to the case of fault (routing loop).
In general, two common problems affect routing algorithms during the transient: black holes and routing loops.
Black holes
editA black hole is defined as a router which, even if at least a path exists through which it could reach a certain destination, does not know any of them (yet).
- Effect
The effect on data traffic is limited to packets directed toward the concerned destination, which are dropped until the node updates its routing table and acquires information about how to reach it. Traffic directed to other destinations is not affected by the black hole at all.
Routing loops
editA routing loop is defined as a cyclic path from the routing point of view: a router sends a packet on a link but, because of an inconsistency in routing tables, the router at the other endpoint of the link sends it back.
- Effect
Packets directed toward the concerned destination start 'bouncing' back and forth (bouncing effect) → the link gets saturated → also traffic directed to other destinations crossing that link is affected.
Backup route
editBackup route is a concept mostly used in telephone networks based on a hierarchical organization: every exchange is connected to an upper-level exchange by a primary route, and to another upper-level exchange by a backup route → if a fault occurs in the primary route, the backup route is ready to come into operation without any transient period.
A data network is instead based on a meshed topology, where routers are interconnected in various ways → it is impossible to foresee all possible failures of the network to prearrange backup paths, but when a failure occurs a routing algorithm is preferable automatically computing on the fly an alternative path (even if the computational step requires a transient period).
Backup route in modern networks can still have applications:
- a company connected to the Internet via ADSL can keep its connectivity when the ADSL line drops by switching to a backup route via HiperLAN technology (wireless);
- the internet backbone is by now in the hands of telephone companies, which have modeled it according to criteria of telephone networks → its organization is hierarchical enough to allow backup routes to be prearranged.
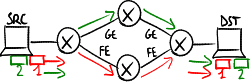
Multipath routing
editWith routing by network address, all the packets toward a destination follow the same path, even if alternative paths are available → it would be preferable to make part of traffic follow an alternative path, even if more costly, not to saturate the path chosen by the algorithm.
Multipath routing, also known as 'load sharing', is a traffic engineering feature aiming at distributing traffic toward the same destination over multiple paths (when available), allowing multiple entries for each destination in the routing table, for a more efficient usage of network resources.
Unequal-cost multipath routing
editAn alternative path is used only if it has cost not too greater than cost of the least-cost primary path:



Traffic is distributed inversely proportionally to the cost of the routes. For example in this case:

the router may decide to send the packet with 66\% probability along the primary path and 33\% probability along the secondary path.
- Problem
Given a packet, each router autonomously decides on which path to forward it → incoherent decisions between routers may make the packet enter a routing loop, and since the forwarding is usually session-based that packet will never exit the loop:

Equal-cost multipath routing
editAn alternative path is used only if it has cost exactly equal to cost of the primary path ( ):


Traffic is equally partitioned on both the paths (50%).
- Problems
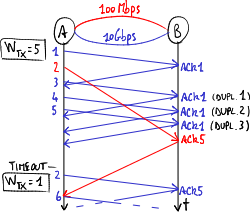
If the first packet follows the slow path and the second packet follows the fast path, TCP mechanisms may cause overall performance to get worse:
- Problems caused by equal-cost multipath routing.
-
 TCP reordering problem.
TCP reordering problem. -
 Transmission rate decrease.
Transmission rate decrease.


- TCP reordering problem: packets may arrive out of sequence: the second packet arrives at the destination before the first packet → the process for sequence number reordering keeps busy the computational resources of the receiver;
- transmission rate decrease: if the acknowledgment packet (ACK) of the first packet arrives too late, the source thinks that the first packet went lost → when 3 duplicate (cumulative) ACKs have arrived and the timeout expires, TCP sliding-window mechanisms get into the action:
- fast retransmit: the source unnecessarily transmits again the packet → the packet gets duplicate;
- fast recovery: the source thinks that the network is congested → it slows down packet sending by limiting the transmission window: it sets the threshold value to half of the current value of the congestion window, and makes the congestion window restart from value 1 (that is only one packet at a time is sent and its ACK is awaited before sending the next packet).
Criteria
editReal multipath routing implementations split traffic so that traffic toward a same destination follows the same path:
- flow-based: every transport-layer session is identified by the quintuple:
- <source IP address>
- <destination IP address>
- <transport-layer protocol type> (e.g. TCP)
- <source port>
- <destination port>
and the router stores a table mapping session identifiers with output ports:
- extracting the fields forming the session ID from the packet is onerous, due to the variety of supported packet formats (VLAN, MPLS...);
- information about transport-layer ports is unavailable in case of fragmented IP packets;
- searching the session ID table for the quintuple is onerous;
- often TCP connection shutdown is not 'graceful leaving', that is FIN and ACK packets are not sent → entries in the session ID tables are not cleared → it is required a thread performing sometimes a cleanup of old entries by looking at their timestamps;
- packet-based: the router sends the packets having even (either destination or source or both) IP address to a path, and odd IP address to the other path → the hashing operation is very fast.
- Problem
Traffic toward a same destination can not use both the paths at the same time → there are troubles in case of very big traffic toward a certain destination (e.g. a nightly backup between two servers).
Non-adaptive algorithms
editStatic routing
editThe network administrator manually configures on each router its routing table.
- Disadvantage
If a change in the network occurs, routing tables need to be manually updated.
- Application
Static routing is mainly used on routers at the network edges:

- edge routers are not allowed to propagate routing information toward the backbone: the core router stops all the advertisements coming from the edge, otherwise a user could advertise a network with the same address as an existing network (e.g. google.com) and redirect towards him a part of traffic directed to that network.
Since users can not advertise their own networks, how can they be reachable from outside? The ISP, which knows which addresses are used by the networks it sold to users, must configure the core router so that it advertises those networks to other routers even if they are not locally connected; - edge routers are not allowed to receive routing information from the backbone: an edge router is typically connected by a single link to a core router → a global default route is enough to reach the entire Internet.
Random walk
editWhen a packet arrives, the router chooses a port randomly (but the one from which it was received) and sends it out on that port.
- Applications
It is useful when the probability that the packet reaches the destination is high:
- peer-to-peer (P2P) networks: for contents lookup;
- sensor network: sending messages should be a low-power operation.
Flooding
editWhen a packet arrives, the router sends it out on all the ports (but the one from which it was received).
Packets may have a 'hop count' field to limit flooding to a network portion.
- Applications
- military applications: in case of attack the network could be damaged → it is critical that the packet arrives at destination, even at the cost of having a huge amount of duplicate traffic;
- Link State algorithm: each router when receiving the network map by a neighbor has to propagate it to the other neighbors:
 A4. The Link State algorithm#Flooding algorithm.
A4. The Link State algorithm#Flooding algorithm.
Selective flooding
editWhen a packet arrives, the router first checks if it has already received and flooded it in the past:
- old packet: it discards it;
- new packet: it stores and sends it out on all the ports (but the one from which it was received).
Each packet is recognized through the sender identifier (e.g. the source IP address) and the sequence number:
- if the sender disconnects from the network or shutdowns, when it connects again the sequence number will restart from the beginning → the router sees all the received packets as old packets;
- sequence numbers are encoded on a limited number of bits → the sequence number space should be chosen so as to minimize new packets wrongly recognized as old packets.
Sequence number spaces
edit- Linear space
It can be tolerable if selective flooding is used for few control messages:
- when the sequence number reaches the maximum possible value, an overflow error occurs;
- old packet: the sequence number is lower than the current one;
- new packet: the sequence number is greater than the current one.
- Circular space
It solves the sequence number space exhaustion problem, but it fails if a packet arrives with sequence number too far away from the current one:
- when the sequence number reaches the maximum possible value, the sequence number restarts from the minimum value;
- old packet: the sequence number is in the half preceding the current one;
- old packet: the sequence number is in the half following the current one.
- Lollipop space
The first half of the space is linear, the second half is circular.
Adaptive algorithms
editCentralized routing
editAll routers are connected to a centralized control core called Routing Control Center (RCC): every router tells the RCC which its neighbors are, and the RCC uses this information to create the map of the network, compute routing tables and communicate them to all routers.
- Advantages
- performance: routers have not to have a high computational capacity, all focused on a single device;
- debugging: the network administrator can get the map of the whole network from a single device to check its correctness;
- maintenance: intelligence is focused on the control center → to update the algorithm just the control center has to be updated.
- Disadvantages
- fault tolerance: the control center is a single point of failure → a malfunction of the control center impacts on all the network;
- scalability: the more routers the network is made up of, the more the work for the control center increases → it is not suitable for wide networks such as Internet.
- Application
Similar principles are used in telephone networks.
Isolated routing
editThere is no control center, but all nodes are peer: each node decides its paths autonomously without exchanging information with other routers.
- Advantages and disadvantages
They are practically the opposite of the ones of the centralized routing.
Backward learning
editEach node learns network information based on packet source addresses: ![]() Local Area Network design/A3. Repeaters and bridges#Trasparent bridge.
Local Area Network design/A3. Repeaters and bridges#Trasparent bridge.
- it works well only with 'loquacious' nodes;
- it is not easy to realize the need of switching to an alternative path when the best path becomes no longer available;
- it is not easy to detect the destinations become unreachable → a special timer is required to delete old entries.
Distributed routing
editDistributed routing uses a 'peer' model: it takes the advantages of centralized routing and the ones of isolated routing:
- centralized routing: routers participate in exchange of information regarding connectivity;
- isolated routing: routers are equivalent and there is not a 'better' router.
- Applications
Modern routing protocols use two main distributed routing algorithms:
- Distance Vector: each node tells all its neighbors what it knows about the network;
- Link State: each node tells all the network what it knows about its neighbors.
Comparison
edit- Neighbors
- LS: needs the 'hello' protocol;
- DV: knows its neighbors through the DV itself.
- Routing table
DV and LS create the same routing table, just computed in different ways and with different duration (and behavior) of the transient:
- LS: routers cooperate to keep the map of the network up to date, then each of them computes its own spanning tree: each router knows the topology of the network, and knows the precise path to reach a destination;
- DV: routers cooperate to compute the routing table: each router knows only its neighbors, and it trusts them for determining the path towards the destination.
- Simplicity
- DV: single algorithm easy to implement;
- LS: incorporates many different components.
- Debug
Better in LS: each node has the map of the network.
- Memory consumption (in each node)
They may be considered equivalent:
- LS: each of the LSs has adjacencies (Dijkstra: );
- DV: each of the DVs has destinations (Bellman-Ford: ).




- Traffic
Better in LS: Neighbor Greeting packets are much smaller than DVs.
- Convergence
Better in LS: fault detection is faster because it is based on Neighbor Greeting packets sent with a high frequency.