Financial Modelling in Microsoft Excel/Printable version
| This is the print version of Financial Modelling in Microsoft Excel You won't see this message or any elements not part of the book's content when you print or preview this page. |
The current, editable version of this book is available in Wikibooks, the open-content textbooks collection, at
https://en.wikibooks.org/wiki/Financial_Modelling_in_Microsoft_Excel
Overview
Financial models need to be:
- useful – they need to assist the user in solving the business problem
- This needs good business analysis and design skills
- accurate – they must do exactly what they say they do
- This needs correct logic, accurate calculations & relevant results
- flexible, so they can evolve throughout the analytical process and beyond
- provable – the inputs, calculations and results can all be verified
This needs clear layout, good documentation, data validation & results testing.
A good guiding rule is to keep things as simple and as clear as possible, for example:
- using common functions rather than complex or rarely used functions
- keeping formulae short
- not being "clever", which may just confuse other people
- separating the spreadsheet into clearly marked sections
Code Complete, the classic book on programming by Steve McConnell, says that managing complexity is the major imperative.
Specifying a model
Find out first –
- what exactly it is for, & what it needs to do
- what inputs it needs and where the data & assumptions will come from
- what business logic is required
- what level of detail it needs to provide
- what flexibility is required – i.e. what needs to be able to change
- who will use it & how, & what are their skills
- how often it will be used, & for how long
- how soon it is needed
For anything except a small model with a clearcut specification and design, it is a good idea - and essential in many cases - to document the specification clearly,
It is extremely important to fully understand and document the business logic, i.e. all the business rules that need to go into the model. For example, most business models involve tax, so you’d expect some rules on how tax affects the model. As you will see, errors in logic – and especially omissions – are among the hardest to find – and they can be extremely dangerous.
You should always ensure you have copies of all relevant correspondence or documents, and anything that will help you understand the business. For example, if you are modelling a workers’ compensation portfolio, you would need documentation on the benefits that are paid, previous actuaries’ reports, publications that might indicate recent trends or issues, etc.
Where other people will be using the model, ensure you know their skill level and experience, and find out how they will use the model (e.g. daily or weekly; briefly or for hours on end; in depth, using all the features, or just using basic features; etc.). It doesn’t matter how clever your model is, if no-one can use it!
Writing a specification
editA specification is a written description of your model. It should cover
- what your model will and won’t do
- what data and other information it needs
- what results it will produce
- documentation and support (if applicable)
- maintenance (if applicable)
- timing
- cost
Design patterns
Design patterns are used where the same set of needs comes up over and over again. They are standard and well-tested approaches to designing models, and you can build up a library of patterns to make it easier to design professional solutions.
Please note that the names of the patterns below are not official names, because Excel has no generally accepted patterns, but they have been created for the purposes of this book. You may not find these names used anywhere else.
Tabular pattern
editThe tabular pattern below is one all spreadsheet users are familiar with.
This is the simplest and most obvious way to build models, and it is used for most business spreadsheets.
It has two main problems:
1. the formulae must be copied down correctly in each column – this is a common error
2. it can be hard to check formulae, when they are crammed into successive columns. There is little room for any explanation, users can only see one formula at a time (unless they turn on the formula view, and then you can't see the values), and users can only see a few columns at a time. This means that as a model gets more complex, this pattern can become very difficult to follow, and even unworkable.
Block pattern
editIn more complex models, it may be difficult to fit everything into one sheet using the tabular pattern above.
The model can be divided into sections such as tax, depreciation, revenue cashflows, etc., and each of these can be put into a separate "block", usually on a separate sheet. The results are then consolidated in a summary sheet.
This is a pattern commonly used in large finance models, e.g. for toll roads, power stations, etc., where a large number of cashflows are projected forward in time, and where the model can be broken up into logical chunks. The models can get very big, e.g. 15 meg, with 3,000-4,000 unique formulae.

The advantage is that each sheet can be checked independently, and each sheet is on a particular topic. When a problem is complex, it helps if you can check it a piece at a time.
More on project financing
While this approach helps break up a complex problem into bite-size chunks, it is important to check the connections between the chunks and ensure they link up properly, as large models can become very confusing. You also need to design the model very carefully because it will be very difficult to rearrange later.
Merge pattern
editThe following approach is a powerful alternative to the tabular pattern. It works well where you have to carry out a series of calculations for many rows of data.
You first build a calculation sheet based on a single record of data,
- showing that data at the top of the sheet,
- listing any assumptions you need (explaining as you go), and then
- setting out the calculations down the sheet, as spread out as you like.
The result is that, given any one of the data records (i.e. rows), you can produce the correct results clearly and accurately for that single row.
This has obvious benefits in making the calculations much easier to check than when they are crammed into columns on a single row, next to the data. Of course, there is no free lunch, and the disadvantage is that you can only do one row at a time, which is clumsy.
The next step is to use a dozen lines of VBA code to load each data record in turn into this sheet, calculate, and export the results for each record into a separate row on an output sheet. You end up with an output sheet with a row of results for each data record.
There are several advantages to this:
- you use a single set of worksheet calculations for all records – there is no need to copy them down all the rows for each record
- the calculations are much easier to check than the tabular pattern, because you can spread them out across an entire sheet, and you can pull any data record in to look at it in detail
- all the business logic is in the worksheet, not in VBA, which simply automates the process
- the data and results sheets are completely separate from the calculations sheet, and they have no formulae that can be messed up - this separation is a very important design principle
- if you want to print individual results for each record (e.g. you want to send out letters to each person), VBA can print a specially formatted output sheet for each record as it loops through them all
This approach requires more skill to build than the tabular approach, but the code can be made generic, so it does not require any changes, removing the need for programming skills.
VBA pattern
editVBA can be used to read in the data and assumptions, carry out all the calculations, and then put the results back in the sheet.
This is a very powerful approach where there are large amounts of data, or where a worksheet would be very slow, because
- VBA can process data extremely quickly, and
- it can read from and write to data files, databases and websites,
- and it is very compact, because all its calculations are done in memory and are discarded once the results are put back in a sheet
The power comes at a significant price, because
- VBA requires sound programming skills
- it can be difficult to adapt later if it needs to change
- it can be very difficult to check, although one solution is to produce a test worksheet with selected outputs to make it easier to see what is happening
Generally, VBA should be used for complex models involving a lot of data, like a simulation or a very large datafile.
Building for safety
The more you work with spreadsheets, the more you will see how inventive people can be in making mistakes, or in misunderstanding what was intended. You have to assume that if it can be read the wrong way, someone will read it wrong.
The guidelines below are all aimed at making it harder to make mistakes.
Inputs and Data
edit- Separate inputs & assumptions from calculations (this is crucial)
- Label & colour input cells clearly
- Protect & constrain inputs with data validation or user controls
- If you are importing data, keep it separate from the calculations
- Give important variables range names, and use them in formulae
- Treat constants (e.g. tax rates) as (unchangeable) inputs – never hard code them into formulae as numbers
- Clearly explain anything that may be unfamiliar or confusing
Formulae & Calculations
edit- Protect calculations – on a separate sheet, or protect the sheet
- Flow calculations from left to right, top to bottom, to echo Excel's calculation sequence, and also the way people will "read" the spreadsheet
- Highlight any cells with inconsistent formulae (i.e. different to neighbours) – preferably don’t do this at all because these anomalies can be very hard to find and may be overwritten if someone else makes a change and copies it down a whole column!
- Use colours carefully – keep bright colours for warnings
- Use a consistent layout & design between sheets
- Use consistent magnitudes/time intervals (e.g. months or years)
- Show sources (references, links to source documents, extracts)
- Include anomaly checks and self-tests (e.g. cross-totals) so that the model checks itself as much as possible
- Don’t be clever! e.g. don’t use obscure functions that no-one else understands
- Don’t create incredibly long formulae – rather use more columns
- Don’t distract or confuse the checker
Results
edit- Set results out clearly and unambiguously
- State all key assumptions, especially in printable results
- Put date (and version number if any) on printouts
Testing
The most important thing to remember is that you are the last line of defence. You aren’t just there to look for typos, and anything you miss could cost a lot of money or embarrassment, so be careful and don’t rush.
In the notes that follow, we’ll assume we are checking a model which is important enough to spend a day or two checking, and that we definitely want no errors. We’ll also consider what can be done to make a model easier to check.
We’ll use the words “check”, “test” & “review” a lot below. They all have the same objective – ensuring the model is correct, or close enough to correct
Before you start
editWe’ll start with some basic questions before getting into the checking itself.
1. Are you the right person to check the model?
- Do you understand the business issues behind the model? This is important because you need to ensure that nothing has been left out, e.g. tax considerations. If you don’t know much about the business, then you probably shouldn’t be checking the model.
- Do you understand enough about the technicalities of the model to check it? If it is written in VBA and you can’t read it, then it’s going to be tough.
- Have you built models yourself? Are you experienced in what can go wrong?
2. Do you have all the documentation for the model?
This should include all relevant correspondence or documents, and anything that will help you understand the business which is being modelled.
3. Do you have enough time and budget to do the job properly?
Getting ready
editMake a copy of the spreadsheet, rename it, and add a sheet called ‘Review’, which will hold all of your comments. Don’t work off the original spreadsheet.
The Review sheet should have some columns like the following:

In practice, most checkers in business work with the original spreadsheet, making corrections or changes and then giving it back to the builder to check.
This is OK for most small spreadsheets, but it does confuse the role of builder and checker and you should avoid doing this for important or complex models. If you use a Review sheet, you should not make any changes to the original – the builder should do this after looking at your comments, and then give the model back to you for rechecking. Your job is to check, not to build.
Checking the functionality
editThe first thing to check, of course, is whether the model does what it is supposed to. You need to find out who wants it and what they asked for, and whether the model is adequate.
In our example of an annuity model, the specification is pretty clear about what is needed, so it should be quite easy to see if it appears to provide everything that was required.
Checking the logic
editThis is a crucial step, because research shows that logic errors and omissions are hard to pick up. This means you need to be extra careful.
Then you need to check the business logic in the model, before getting into the detail of sheets and cells. Hopefully, the model builder has documented the logic clearly to make it easier to check. This means not only setting out the logic itself, but providing a link to, or an extract of, original documentation, to show where it came from. If this is not the case, you should request that this be done.
The extract below is from an actual spreadsheet which calculates a profitability formula using a previous report, an extract of which is included on the right. This makes it easy for a checker to review the logic.

You can see that this is much better than if the model builder simply began using a mysterious formula like =1-1/(G6+(1-G6)/0.85), without explanation.
As far as possible, you should write out your own logic before looking at the model, because it is easy to be influenced by what you see, and think “That looks OK”, whereas if you’d done it yourself first, you might have spotted something missing.
Identifying the risk factors
editNow you understand what the model is supposed to do, and you have worked out the business logic, you should think about what could go wrong, and how serious that could be.
For example,
- some of the inputs might be dangerous, because users might put in incorrect values by mistake or through ignorance
- there may be combinations of inputs which require different treatment
- some assumptions (e.g. tax rate) may have a significant effect on results
- which inputs or calculations have most effect on the results?
- formulae may not have been copied correctly across rows or columns
At this stage, you should also think about how you can check the model for reasonableness.
Checking the inputs
editYour inputs will normally include some or all of
Data: e.g. employee records, or transaction records. You need to check where the data came from, and that it is correct, and that it has not been altered. Ideally, it should be kept completely separate from the rest of the model (e.g. in a separate worksheet or datafile), to avoid contamination.
As with everything else, the data needs to be clear. If, for example, there are confusing or mysterious headings, there should be notes to explain them.
Assumptions: these are the assumptions underlying the model, which are set by the builder and not by users. For example, the model may include a set of the current income tax rates, which obviously don’t need to be input by users because they are the same for everyone.
The assumptions should be set out clearly in one place, clearly labelled and with explanations, and if they are date-sensitive (e.g. tax limits which are changed every year), the effective date should be shown. The cells containing values should be colour-coded to pick them out.
The assumptions need to be documented and justified, because they can have such an effect on the results. If you don’t feel that you could explain the reasons for the assumptions to another actuary, you haven’t done enough work.
If it hasn’t been done already, figure out the limits for assumptions, for example, salary growth may be shown as 4%, but you may decide that it may vary between 0% and 8% in a year. This is important in checking that the model can deal with extreme inputs, and also in checking any sensitivity testing.
User inputs: this generally only applies where there are going to be users other than the model builder. User inputs can be very dangerous, because users can be very imaginative in what they enter. For example, if asked for an interest rate, they could put in any of 0.7, 7% or 7. The model has to deal with this.
For this reason, user inputs should be “controlled”, by constraining them to valid inputs. Excel’s data validation is the most powerful way to do this, because it will prevent users entering inputs that don’t fall in ranges you specify, or typing in text that isn’t on a list you specify, etc.
An alternative is to use the “controls” that Excel provides, e.g. dropdowns & checkboxes.
As a checker, you should look at the way the inputs have been modelled, and think about what users could do to break the model. How strict you need to be will differ for each model, of course.
You should also check that the user inputs are explained well enough for an average user to understand them.
Checking the calculations
editThe calculations are where the inputs meet the business logic. This is where it is most important to lay the calculations out clearly and in detail, to make it easier to check them.
The most obvious approach is to follow the layout of the calculations and check the way in which the data, assumptions, inputs and logic have been combined to produce the eventual results.
Most commonly, the data is in rows, and formulae are in columns.
Formulae should run from left to right, top to bottom, both because this is how we read, and because Excel calculates in this order. Inputs should be at the top left, or on their own sheet.
Things to look for:
- formulae unexpectedly changing in the middle of a table - this will be easiest to spot if you change the font to a monospace font, e.g. Courier, and then, with a click of the Show Formulas button in the toolbar, reveal all the formulae on the sheet
- hard coded numbers (e.g. tax rates) in formulae – these should be taken out and included with the assumptions, even if they are unlikely ever to change
- circularity – should be avoided if at all possible
Running tests
editThe next step is to run some tests on the inputs. A simple technique is to set all the inputs to 0 or 1 (or whatever) so that the results are very simple indeed and any anomalies jump out immediately. For example, a financial projection with the investment rate and indexation set to nil should just produce a list of unadjusted cashflows, making it easier to see if they are correct. Another technique is to use “corner” inputs, i.e. put in the highest and lowest values for inputs and see if the model works correctly.
You should think about what will happen if you do all your tests and find an error, and then you have to redo all the tests again when the error is fixed. This could get a bit tedious! Depending on the effort involved, you could set up an automated set of tests.
If the model is for internal use, you should try to include your tests in the model itself, so that anyone using it can see exactly what was tested, and perhaps even retest it.
If you can write code, it may be a good idea to set up a set of inputs and use VBA to run through them automatically. This can greatly speed up testing.
Where the business logic is written in VBA (i.e. VBA is doing most of the hard work), it may be difficult to test. You may be able to dump partial results to a sheet for testing.
Reasonableness tests
editYou should look for ways to test the reasonableness of the model. For example, there may be figures that were done a year ago which should be similar to the results of the model, or there may be other models which can be used to produce test results for at least part of the current model.
You can also ask the builder to include cross-checks (e.g. totals for columns and rows should match) which help in testing the model.
Sensitivity testing, i.e. changing one of the inputs and seeing what happens, is another way to test for reasonableness, especially if you have some idea of what to expect.
An extension of sensitivity testing is to find out how accurate the model needs to be, then estimate the possible errors in setting the assumptions and inputs (for example, an investment assumption of 7% might be out by 2% either way), and test the impact on the results. This gives a rough idea of how far out the results might be (because the user can’t possibly get all the assumptions absolutely correct), and whether the overall error is acceptable.
Test in chunks
editIf possible, test the model in chunks, so you can sign it off one part at a time. This makes checking more manageable and it should make finding errors much easier.
Spreadsheet testing tools
editThere are several spreadsheet testing tools which can help in checking complex spreadsheets. They look for things like inconsistent formulae, & orphan (unused) calculation cells.
Is it usable?
editPut yourself in the shoes of the user, or, even better, find someone else to try using it. Is it clear, or is it confusing?
Can users accidentally change formulae, or put in ridiculous figures?
Remember that users will often not read instructions, and will use the model without thinking. The less expert the user, the more effort needs to go into protecting the model – and especially the inputs – from incorrect use.
Analysis
Making sense of the results is crucial. The first test is that your results give you the information you need to analyse the client problem.
Then you need to play with the model to test the effect of different inputs, to get a feel for the sensitivity to change. Ideally, you want results which are robust (i.e. they are not too sensitive to your inputs).
Testing the effect of uncertainty
editAll financial modelling is uncertain, because we can’t predict the future, and things may not go according to our assumptions.
The power of models is that they are dynamic (this was seen as a key advantage of the first spreadsheet, Visicalc). You can change an assumption and see the effect immediately.
Read this paper [1] on project financing, especially section 3.2, for more on sensitivity testing.
Base case
editYou will usually start with a “base case” set of assumptions and inputs. These are your best estimates, and you would use these to produce a set of expected results.
Scenario testing
editIt is common to set up alternative scenarios, e.g. pessimistic, expected and optimistic, and run them through a model. Each scenario will consist of a set of assumptions and inputs chosen by the user. Importantly, the assumptions need to be consistent, so for example, if you assume inflation is only 2%, salary growth is likely to be low as well.

This approach is very useful for business planning and risk management, because it shows the impact of different conditions.
Scenario testing is quick and it is easy to present the results to management, to show them best & worst case extremes. On the other hand, it can’t tell you how likely it is that each scenario will occur, or whether there are other important scenarios that need to be tested. You are relying entirely on the skill and experience of whoever sets up the scenarios, and hoping they thought of everything.
To summarise, this approach
- lets us see the effect of a worst case and best case alternative to our expected result,
- is simple to set up in a spreadsheet, &
- makes it simple to present alternatives to clients.
The weakness is that
- you don’t know how likely each scenario is,
- you can’t give an estimate of the average result, taking into account the full range of alternatives, and
- you can’t estimate the range of likely results or produce percentiles.
Note: Excel has a “scenarios” feature which lets you store values for a number of inputs under a scenario name. The problem is that the scenario details are hidden. It is better to set up all the scenarios in a table (like the example above) so they can be compared easily.
Stress testing
editStress testing is linked to scenario testing. Suppose you have built a model of an insurer’s financial position into the future. You would “stress test” the insurer by setting up various catastrophe scenarios and then modelling the financial position in each case. Ideally, the insurer will survive each one.
Stress tests can be based on actual past events, or on imagined events.
Like stochastic testing (below), it can be difficult to set the assumptions, as this extract of a US report on one of their housing agencies shows:
With basic model development complete, we are now well into sensitivity testing; that is, running complete sets of actual Enterprise data through the model to evaluate the appropriateness of various "settings" of its components for the stress test.
For example, we must determine the appropriate specification governing the shape of the Treasury yield curve, the relationship between Treasury rates and Enterprise borrowing rates, and the relationship between house prices and interest rates. These full-fledged simulation runs help us evaluate stress test options, and also provide the additional benefit of helping to identify possible model anomalies or program bugs that we need to address.
This is standard in a model development project of this type.
Sensitivity testing
editA model can also be used to show the impact of changing one assumption, or perhaps a few linked assumptions. This sensitivity testing can show which inputs have the greatest effect on results.

Sensitivity testing can also test if the model is realistic, because users will generally have some idea of what to expect when they make a change.
Sensitivity testing can also help show whether a model is accurate enough. Suppose, for example, a company has a budget model, and it needs a model to be accurate to within $2 million. Sensitivity testing might show that the assumption with most impact is the investment rate, and that a change of just 0.5% in that rate has an impact of $2 million. This means that the user has to choose an investment assumption that is no more than 0.5% different from the actual rate (which we don’t know yet, because it is in the future). If the user can’t be sure of being this accurate, then the model can’t deliver the accuracy that the company wants.
Sensitivity testing is a powerful way of spotlighting parts of the model. It deepens your understanding of how the model reacts to change, and you should use it to gain familiarity with new models that you have not worked with before.
Sensitivity testing has its limitations. You have to be careful how much you change each assumption, and how you compare the sensitivity of one assumption against that of another.
Because it focuses on changing one (or maybe a few) elements at once, to see the effect, you can’t get a feeling for worst or best cases, nor for the probability of good or bad results. So it should be used together with other tests, and not on its own.
Probabilistic stochastic testing
editStochastic testing uses random numbers to simulate a large number of alternative scenarios that might happen in real life. We can then calculate percentiles to get some idea of the probability of different financial outcomes.
Example: an actuary wants to assess the likelihood that a fund will be insolvent in the future because of poor investment returns. She uses an investment model to produce (say) 1,000 separate sets of simulated investment returns, which might look something like this….
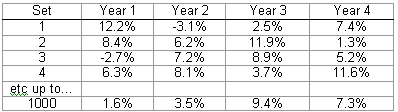

Each set of rates is put into the model, so there will be 1,000 sets of results. These can be sorted to find (say) the 10% and 90% percentiles, which gives the actuary a feel for how well – or badly – things could go in future.
Stochastic testing has the great benefit that it gives you a much better feel for the possible range of experience, either high or low.
Unfortunately, it is also the most complex to build, and it requires more complex assumptions, e.g. a statistical distribution for interest rates, and another for salary growth – and you have to consider whether there is a correlation between them that needs to be accounted for, so perhaps the distributions are connected.
It is very difficult to build a stochastic model of investment markets because of all these issues. It is much easier to model mortality stochastically.
Stochastic testing as a search tool
editThere is another way to use stochastic testing in your analysis. If you have a number of inputs, and each of them can vary in a range, then that is a very large number of combinations of inputs that may need to be tested in case they are important.
A simple way of approximating this is to create a large number of sets of inputs stochastically, i.e. choose each input randomly within the range you have set for it.
Below is an example….

etc.
Each of these sets can be run through the model, and the results sorted to see if there is any pattern, e.g. what inputs always give a high result, for example?
This is a quick and dirty way of trying most combinations of inputs.
Dynamic analysis
editSome models need to include a feedback loop because the assumptions and inputs would not stay fixed over time, in the real world.
For example, if you are modelling a pension fund, and the assets fall below liabilities, the employer would most probably make extra payments to remove the shortfall. Your model may need to allow for this by including an algorithm that models the employer response to the financial position.
If you are modelling a banking nor financing institution and , somehow debit transactions sums up to be more than credit transactions , than we do need have to loop around to read the transactions again.