This material has some significant problems; see the Talk page. |
What is Syntax?
editSyntax is the how and why of sentence’s structured: the relationship between elements of a sentence and what those relationships encode. It’s the way a language organizes bits of meaning into representations of the world, of ideas, of situations, etc. Without syntax, there’d be no way of putting any particular meaning into sounds or symbols, and there’d be no way of getting a particular meaning out of sounds or symbols. In short, without syntax, there’s no language, just like without meaningful components there’s no language.
Some examples of word order affecting grammaticality:
- 1) The dog bit the man.
- 2) The dog is brown.
- 3) *Man bit dog the the.
- 4) *The is brown dog.
Some examples of word order affecting meaning:
- 5) The man bit the dog.
- 6) The dog bit the man.
- 7) Is the dog brown?
[Note: An asterisk before a sentence indicates ungrammaticality. A superscript question mark before a sentence indicates questionable or unknown grammaticality, or grammaticality to only some speakers.]
Syntax generally describes two things: where certain things can go, and what those positions mean. At this level we’ll be looking at various languages and comparing the different ways languages achieve the same thing. Later, in the advanced syntax tutorial, we’ll go back and attempt to find out if it’s possible to describe all languages using the same fundamental syntactic rules and structures, and why they seem to be so very different.
Unlike the simpler approach to syntax, this tutorial will be an in-depth look at linguistic theories. Where traditional approaches just discuss things like SOV vs. SVO vs. etc. word order, or such, this tutorial will explore the underlying structures and rules that produce those word orders. In the advanced syntax tutorial we’ll see how the rules we develop shed more light on the situation, and prompt us to throw out the simplistic notion of SOV vs. SVO vs. etc. word order as being a fundamental concept in syntax.
This tutorial will deal with some of the preliminary concepts used in syntax, primarily the structural components of sentences. As we’ll see by the end of the tutorial, we can account for a large number of features of languages with just this approach, but that we still miss a significant portion of what languages do in fact produce. The advanced syntax tutorial will take us into new territory, exploring a few different theories that aim to account for still more of language. Both this tutorial and the advanced syntax tutorial will be following the general structure of Andrew Carnie’s Syntax: A Generative Introduction (2nd edition), and could be considered a conlanger’s summary of that book. If you’re serious about understanding syntax from a P&P perspective, that book is highly recommended.
What's in this section?
editThe parts of this section are:
- Parts of speech: What classes do words fall into?
- Constituency, trees, rules: How do words combine?
- Structural relationships: How do words and combinations relate to one another?
- Binding theory: Why do pronouns seem to behave oddly?
- Linguistic universals: How do the syntaxes of various languages pattern?
- Applying knowledge: How do you apply this knowledge in creating a language?
- Finding problems: What problems still exist in this theory?
Parts of Speech
editSentences, as we all know, are made up of words. But not all words are alike; some words represent objects, some represent actions, etc. What a word represents — its part of speech or syntactic category — plays a significant role in its behavior in a language’s syntax. We can identify two major categories of words. Lexical parts of speech convey whole meanings in themselves, and consist of categories like noun and verb. Functional parts of speech, on the other hand, show relationships between words, or provide extra meaning to words, and include categories like preposition and conjunction.
Lexical
editThe lexical parts of speech can be divided into the four major categories of nouns (N), verbs (V), adjectives (Adj), and adverbs (Adv). These categories aren’t necessarily universal, and what distinguishes them from one another is a matter of how they behave. Identifying a word as noun or verb is done by looking at what it does: a word is a noun because it behaves like a noun, etc. These particular categories are specific to English and many Indo-European languages, and because this tutorial is in English, and will focus primarily on English syntax, these are the categories that’ll be used.
Nouns
editThe typical way of describing what nouns are, in informal or grade school English grammar, is “person, place, or thing”. Nouns can also be emotions, colors, abstract concepts, etc. Nouns can often have quantity, specificity, properties as shown by adjectives, roles in an action, etc.
Verbs
editVerbs are usually actions, involving some change, or states of being, involving one manner of being vs. another. They often can be described as having tense (when it occurred), aspect (how it occurred through time), manner as shown by adverbs, participants as shown by nouns and other phrases, etc.
Adjectives
editAdjectives describe qualities of nouns. They can represent colors, shapes, or more abstract qualities like true, honest, or absurd. Adjectives themselves can have quality or manner, described by adverbs.
Adverbs
editAdverbs describe qualities of non-nouns, i.e. verbs, adjectives, and other adverbs. They’re perhaps the most abstract of the lexical categories. For example, quickly is an adverb that describes the speed of a verb, but there’s no quality of quickness in an action that can be measured, it’s a very abstract and relative notion compared to a quality such as red. Adverbs like very are even more abstract.
Functional
editFunctional categories are even harder to conceptualize than the most abstract adverbs. They convey things like tense, ability, permission, and aspect of verbs, relationships between phrases, specificity of nouns, etc. Some common functional categories in English are prepositions (P), determiners (D), conjunctions (Conj), complementizers (C), tenses (T), and negation (Neg).
Features
editFeatures are abstract semantic properties that can be used to describe words. Some, such as purality, are not as abstract as others, such as modality. They tend to be extra information about a word that’s relevant to the structure of the sentence, governing the relationship between the word and other words around it. Features are generally written between brackets. Having a feature is indicated by prepended “+” to the feature, lacking it is indicated by prepending “–”. Multiple features are separated by commas.
Some examples of features:
- [+plural]
- [–definite]
- [+past,+inchoative]
- [+Q,–WH]
In the advanced tutorial we’ll see how features themselves can be indicated lexically, and how features can exist in certain places and affect the behavior of words in a sentence to convey certain meanings.
In looking at how various types of words behave, we find that they end up dividing into various classes that govern how they can be placed in a sentence. In some languages these subcategories can be overtly marked on the words (Spanish, for instance, has overtly marked gender subcategories, which governs verb agreement), while in others the subcategories are covert and don’t show any markings of the subcategory they belong to.
In English, nouns can be divided into two categories, count nouns, which represent individual countable items, and mass nouns, which represent uncountable things or substances. Count nouns require an indication of number, while mass nouns don’t:
- *Dog bit the man.
- A dog bit the man.
- The dog bit the man.
- Dogs bit the man.
Count nouns can also be used only with certain quantifiers, while mass nouns certain others:
- many cats
- *much cats
- much water
- *many water
If we want to label these nouns for subcategory, we can do so with features. For instance, the distinction between count and mass nouns can be marked with the feature [±count]:
- dog[+count]
- cat[+count]
- water[-count]
Verb Subcategories
editWe can also look at some subcategories of verbs in English. By examining the number of arguments a verb takes, and where they’re positioned in the sentence, we can find some useful properties of verbs.
Just by looking at the number of arguments a verb takes (its valency) we find three kinds of verbs in English. Intransitive verbs take only one argument, the subject, transitive verbs take two arguments, the subject and the direct object, and ditransitive verbs take three arguments, the subject, the direct object, and the indirect object. Some verbs seem to have optional transitivity, such as the verb “drive”: You can say “I drive.” but you can also say “I drive a car.”. In these situations we can say that there are actually two verbs with different valency.
Verbs can also require certain things in certain places relative to them in the sentence. Intransitive verbs require their argument before them. We can indicate this with a feature such as [NP __], with the underscore representing the position of the verb and with NP representing a Noun Phrase. Transitive verbs require an argument before them and after them, and this can be indicated by the feature [NP __ NP] or [NP __ {NP/CP}] (CP for Complement Phrase). The curly braces enclose alternate options, separated by slashes. We say that the object of some transitive verbs can be either an NP or a CP because we have examples like “I said nothing.”, as well as “I said that the pie was tasty.”. Ditransitive verbs can be described with yet another feature.
Here’s an example table of English verb subcategories, with their matching features, and with examples:
| Subcategory | Example |
|---|---|
| Intransitive: V[NP __] | Leave |
| Transitive Type 1: V[NP __ NP] | Hit |
| Transitive Type 2: V[NP __ {NP/CP}] | Ask |
| Ditransitive Type 1: V[NP __ NP NP] | Spare |
| Ditransitive Type 2: V[NP __ NP PP] | Put |
| Ditransitive Type 3: V[NP __ NP {NP/CP}] | Give |
| Ditransitive Type 4: V[NP __ NP {NP/PP/CP}] | Tell |
Constituency, Trees, Rules
editA constituent is any group of items in a sentence that are linked to one another to form a unit. So far the only constituents we’ve seen are words, but there are other sorts of constituents too, namely, phrases. Phrases are groups of words or phrases that are connected more closely to one another than to words and phrases outside the group. In general we say that every phrase has a head (a word) and every head projects a phrase, but this isn’t always the case. A head of a particular syntactic category projects a phrase for that category: a noun (N) projects a noun phrase (NP), a verb (V) projects a verb phrase (VP), etc. We can also say that phrases can be composed of two conjoined phrases of the same time, without having a head.
We can see constituents in sentences just by asking if two words are more closely related to one another than to something else. For example, in “the dog bit the man”, we would say that “the” and “dog” form a constituent with one another, “the” and “man” form a constituent, and so on. Knowing which form of phrase is formed depends on what’s more central to the meaning of the constituent. “The dog” and “the man” are more about “dog” and “man”, respectively, and not as much about “the”, so each of those constituents would be NPs.
Showing the Constituency Hierarchy of a Sentence
editBrackets
editThere are two ways of showing constituency. The first method is by using brackets. This is the easiest to do in text, because it doesn’t involve any special shapes or such. The general way of showing constituency is by putting brackets around a constituent and putting the type of constituent in subscripts after the first bracket. The two identified constituents from the previous example sentence would then be:
- 1) [NP [D the] [N dog]]
- 2) [NP [D the] [N man]]
Sometimes you’ll see some constituents incompletely bracketed, such as
- 3) [NP the dog]
- 4) [NP the man]
This occurs when the structure that’s been neglected is irrelevant to whatever is being demonstrated by showing constituency. You might also see bracketing without labels (e.g. [the dog] for [NP the dog]) when the labels are irrelevant or recoverable from context. When you’re beginning with constituency it’s better to fully indicate constituency, regardless of relevance.
Trees
editMore common for showing the structure of a sentence is the tree diagram. In trees, constituents are represented by nodes connected by lines. Lines connect up from one constituent to another that encloses it. The nodes themselves are the type (N, NP, V, VP, etc.). Heads (N, V, etc.) often have the actual word written below them. The tree versions of [NP [D the] [N dog]] and [NP [D the] [N man]] are shown below.
- 5 & 6)


 Triangles are used to indicate that the constituency isn’t fully shown.
- 7 & 8)
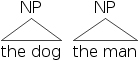

 One general rule for drawing tree structures is that lines never cross. In other words, a constituent must be formed by adjacent items. In the advanced syntax tutorial we’ll explore how non-adjacent constituency is handled and why it arises.
Describing Allowable Constituency Hierarchies
editShowing constituency via bracketing and trees is useful for describing what a particular sentence looks like, but syntax is about describing how all sentences look like, and what rules are followed by those sentences. What we need, then, is some way of describing what constituents are acceptable, and what’s contained within them. Looking at the simple examples “the dog” and “the man”, we can derive some basic rules for English NP. In each we have a determiner followed by a noun. If we were to reverse these, giving “dog the” and “man the”, we get ungrammatical phrases, so we can say that an NP consists of a D followed by an N. We can represent this more succinctly as
- 9) NP → D N
English, of course, also allows collections of adjectives, AdjP, before a noun, but after the determiner, as in “the big dog” (but not as in “big the dog” or “the dog big”), and prepositional phrases, PP, after the noun, as in “the dog in the house” (but not as in “in the house the dog” or “the in the house dog”). So English NP’s can be described more fully like so:
- 10) NP → D AdjP N PP
We can use X, Y, Z, etc. as metavariables indicated an arbitrary head type. If something is optional, we put it inside parentheses, as in (XP). Alternating choices are put inside braces and separated by forward slashes, as in {XP/YP}. If you need to have any number of an item, for example “XP or XP XP or XP XP XP or ...”, you can put one of the items append a “+” after it, as in XP+. These can be combined to create multiple optional items — (XP+) being no XP, one XP, two XPs, etc. — or multiple instances of a collection of items — {XP/YP/ZP}+ being one or more phrases, each of which can be either an XP, YP, or ZP — and so on.
These rules, with a phrase on the left of an arrow and the contents of that phrase on the right of the arrow, are called Phrase Structure rules, or PS rules. For English, we can describe a large number of sentences with the following set of PS rules:
- 11) CP → (C) TP
- 12) TP → {NP/CP} (T) VP
- 13) VP → (AdvP+) V (NP) ({NP/CP}) (AdvP+) (PP+) (AdvP+)
- 14) NP → (D) (AdjP+) N (PP+) (CP)
- 15) PP → P (NP)
- 16) AdjP → (AdvP) Adj
- 17) AdvP → (AdvP) Adv
- 18) XP → XP conj XP
- 19) X → X conj X
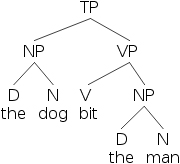
So if we wanted to describe the sentence “the dog bit the man”, we can make this bracketed sentence:
- 20) [TP [NP [D the] [N dog]] [VP [V bit] [NP [D the] [N man]]]]
And as a tree:
- 21)


Tests for Constituency
editTo develop a list of PS rules for a language, it’s necessary to determine what forms constituents. To some extent, it’s possible to do this merely by intuition for your native language, but there are many cases where it’s hard to tell what is a constituent and what is not. To make it easier to determine constituency, there are numerous tests that can be performed on any potential constituent. In the advanced syntax tutorial, we’ll see how these tests give us reason to revise the PS rules, reformulating them as a whole new theory.
Replacement
editOne way to test for constituency is to see whether the potential constituent can be replaced by a single word without affecting the meaning of the sentence.
- 22a) The dog bit the man.
- 22b) The dog bit him.
- 23a) The dog bit the man.
- 23b) It bit him.
In these examples we see pronouns replacing strings of words of the form D N, which suggests that D N forms a constituent. This of course is an English NP. We can then say that anything replaceable by a pronoun is of the same kind of constituent, which allows us to take any collection of sentences and identify examples of pronoun-replaceable constituents to identify what can go into them. This is what gives us the rule for what constitutes an NP.
Stand Alone
editAnother kind of constituency test is the stand alone test (a.k.a. the sentence fragment test). For example, if a group of words can be used as an answer to a question, that is, if it can stand alone as a meaningful independent clause, we can say that it’s a constituent.
- 24a) The dog bit the man.
- 24b) The dog bit the man.
- What did the dog do?
- 25a) Bit the man.
- 25b) *Bit the.
These show that “bit the man” forms some constituent, while “bit the” doesn’t form a constituent in English.* By continuing tests involving V’s we find a definition for VP’s.
* The situation is less clear in languages where "the" and "him/her" have the same form. For example, Spanish la "her" resembles la "the (feminine singular)".
Movement
editMovement tests show constituency by moving a potential constituent without making the sentence ungrammatical. Clefting involves inserting It is or It was before the potential constituent that after it (26). Preposing/pseudoclefting involves inserting Is/are what/who the potential constituent (27). Making a sentence passive, by swapping subject and object, inserting by before the former subject, and turning the verb into passive form (bit becomes was bitten, etc.), will also indicate constituency.
- 26) It was the dog that bit the man.
- 27) The dog is what bit the man.
- 28) The man was bitten by the dog.
Conjunction
editThe last test for constituency involves taking a potential constituent and conjoining it with something else that’s similar.
- 29) The dog bit the man.
- 30) The dog and the cat bit the man.
Constituency Test Failures
editConstituency tests are not always a guarantee. There are situations where a language appears to have constituents that violate other previously identified constituents.
- 31) The cat saw and the dog bit the man.
(31) would indicate to us that “the cat saw” and “the dog bit” each form a constituent, because they seem to satisfy the conjunction test, which is a violation of previously determined constituency rules. Situations like this require further inquiry. One way we can resolve this, which is taken in the Principles and Parameters framework, is by positing that “the cat saw and the dog bit” aren’t in fact a constituence, but instead there’s an unspoken pronoun (i.e. it has lexical content but no phonological content) that’s called pro, which references “the man”. This would allow us to reanalyze (31) as being a conjunction of two full sentences.
- 32) [The cat saw [pro]i] and [the dog bit [the man]i]
Here a subscript “i” is used to indicate that pro and the man reference are the same. In this analysis there’s no violation of the PS rules we’ve previously found for English. Other frameworks will handle this sort of situation differently. Lexical Functional Grammar, for example, doesn’t use pro and instead allows a much looser variety of constituents. This sort of failure of the tests show us that there’s more going on in the sentence than there first seems to be, and we’ll explore various different ways of addressing these apparent oddities in the advanced tutorial.
Structural Relationships
editTrees structures, as previously mentioned, have distinct components, the nodes, that contain or are contained by other nodes. This hierarchy of containment, and co-contained-ness, allows us to identify certain relationships between nodes that are useful in describing why things behave the way they behave in a language.
Parts of a Tree
editStarting with some simple PS rules
- 1) A → B C
- 2) B → D E
- 3) C → F G
- 4) F → H
we can generate a tree
- 5)


 We can now explore the different parts of trees. A, B, ... are examples of nodes. Nodes are connected to one another by lines, which differentiate branches. B, and the nodes below it, form a branch distinct from C and the nodes below C. D is a distinct branch from E, and so on. If a node has only one branch below it, it’s said to be non-branching; if it has more than one branch below it, it’s branching.
- 6)

- 7)
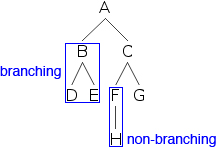


 At the top of the tree we find A, which is not below any other node. Such nodes are root nodes. At the bottom we find D, E, H, and G, which have no nodes below them. Such nodes are terminal nodes (sometimes called leaf nodes). The nodes A, B, C, and F, all have nodes below them, and are called non-terminal nodes. The actual letters given to the nodes are called labels.
Terminal nodes are almost always heads (in the advanced syntax tutorial we’ll say that all terminal nodes are also heads), and all non-terminal nodes are phrases.
Domination Structures
editThe simplest kind of structural relationship between nodes is a dominance relationship. A node dominates another node if it’s above that node in the tree. In the example tree, A dominates all other nodes, B dominates D and E, C dominates F, H, and G, and F dominates H.
- 8) A node X dominates another node Y if and only if X is higher in the tree than Y (i.e. fewer nodes between X and the root node) and you can trace a path between X and Y by going in only up from Y to X or only down from X to Y.
We can also make statements about which collections of terminal nodes are dominated by which other nodes. For instance, the set {D, E} is dominated by both B and A. With B, the set is the same as the set of nodes dominated by B, but with A, the set is only some of the nodes dominated by A. We can say then that B exhaustively dominates the set, but A doesn’t.
- 9) A node X exhaustively dominates a set of terminal nodes {Y, ..., Z} if and only if X dominates all members of the set, and all terminal nodes dominated by X are members of the set.
- 10)


Immediacy
edit We can also notice relationships between how far nodes are from one another in a dominance relationship. Some nodes, such as F, are directly above other nodes, in this case H, while other dominating nodes, such as A, are not directly above. When a node is directly above another node, it immediately dominates that node.
- 11) A node X immediately dominates a node Z if and only if X dominates Z and there’s no node Y that dominates Z and is itself dominated by X.
- 12)


A node that immediately dominates another node is called the mother of that other node. A node that is immediately dominated by another node is called the daughter of that other node. Daughters of the same node are called sisters.
Another simple relationship that can be described in terms of domination is constituency.
- 13) A node X is a constituent of a node Y if and only if Y dominates X.
- 14)


Precedence Structures
editPrecedence is not as simple as dominance, but still quite simple. A node precedes another node if it appears before that node. But there are two distinct kinds of precedence, and one kind depends on the other.
- 15) A node X sister-precedes a node Y if and only if both X and Y are immediately dominated by the same node and X appears to the left of Y.
- 16)



- 17) A node X precedes a node Y if and only if neither node dominates the other and X or a node dominating X sister-precedes Y or a node dominating Y.
- 18)


Immediacy
editImmediacy of precedence can play an important role in the analysis of things like direct vs. indirect objects. Immediacy in precedence is similar to immediacy in dominance, so the definition will be similar.
- 19) A node X immediately precedes a node Z if and only if X precedes Z and there’s no node Y that precedes Z and is itself preceded by X.
- 20)


C-command
editC-command is probably the most useful structural relationship when it comes to building a theory for how a language works syntactically. A c-command relationship should be easy to grasp if you understand dominance and sister-hood. Basically, a node c-commands another node if it’s sister to that node or sister to a node that dominates that node.
- 21) A node X c-commands a node Y if and only if the node immediately dominating X also dominates Y.
You can find c-commanded nodes visually by following a simple rule: Go up one then down one or more, and any node you land at will be c-commanded by the node you started at.
- 22)


Symmetry
editC-command relationships can show symmetry, as well. Symmetry can play an important role in the behavior of certain constituents. Symmetric c-command is essentially a sister relationship. Asymmetric c-command is essentially all other c-commanding situations.
- 23) A node X symmetrically c-commands a node Y if and only if X c-commands Y and Y c-commands X.
- 24) A node X asymmetrically c-commands a node Y if and only if X c-commands Y and Y doesn’t c-command X.
- 25)



Government
editGovernment is another important relationship. It’s built on top of c-command and so it’s easy to define in those terms. It looks very similar to immediacy relationships.
- 26) A node X governs a node Z if and only if X c-commands Z and there’s no node Y that c-commands Z and is itself c-commanded by X.
- 27)


Phrase/Head
editSome government relationships only apply between heads or between phrases. We can define two sub-types of governance based on the types of the participating nodes.
- 28) A node X head-governs a node Z if and only if X c-commands Z, there’s no node Y that c-commands Z and is itself c-commanded by X, and X, Y, and Z are all heads/terminal nodes.
- 29) A node X phrase-governs a node Z if and only if Z c-commands X, there’s no node Y that c-commands Z and is itself c-commanded by X, and X, Y, and Z are all phrases/non-terminal nodes.
- 30)

- 31)

Grammatical Relationships
editThe last kind of relationship is the grammatical relationships. These aren’t structural relationships at all, but rather semantic relationships that tend to end up taking on the same structural form in language after language. Some of these will be revised in the advanced syntax tutorial.
These relationships depend entirely on the PS rules of a language, in this case English.
- 32) Subject (S): The NP or CP daughter of a TP.
- 33) (Direct) Object (O or DO): The NP or CP daughter of a VP headed by a transitive verb.
- 34) Object of a Preposition: The NP or CP daughter of a PP.
- 35)


 English has type of object called an Indirect Object (IO). Indirect objects can sometimes appear as a normal Object or sometimes as the Object of a Preposition.
- 36)

- 37)



 Now that we have two kinds of objects that both can be NP daughters of VPs, we need to redefine the term Direct Object, and also define an Indirect Object.
- 38) Direct Object (v2):
- a) The NP or CP daughter of VP, with a V[NP __ NP], V[NP __ CP], V[NP __ {NP/CP}], and V[NP __ NP PP]
- b) An NP or CP daughter of VP that’s sister-preceded by an NP or PP, with a V[NP __ {NP/PP} {NP/CP}]
- 39) Indirect Object:
- a) The PP daughter of VP immediately preceded by an NP daughter of VP, with V[NP __ NP PP]
- b) The NP daughter of VP immediately preceded by V, with V[NP __ NP {NP/CP}]
There’s another kind of object, the Oblique Object, which is usually marked with a preposition, as in:
- 40) I eat toast [PP with jam].
Oblique Objects can show up in the same positions as Indirect Objects, and sometimes in the position of a Direct Object. What makes an Oblique Object distinguishable from other kinds of objects is whether or not it shows up in the argument feature for the verb. For instance, the verb “eat” has the argument feature [NP __ NP]. If a PP, such as “with jam”, shows up in the sentence, it must be an oblique object, since it’s not indicated in the argument feature.
Binding Theory
editBinding theory is an attempt to account for certain phenomena involving pronouns and anaphors by using the structural framework we’ve developed up to this point. To understanding where this theory comes from it’s important first to understand what these kinds of words do that makes them so special and how they’re set apart from normal nouns.
Normal nouns are what’re called R-expressions (“r” for “referencing”). The have meaning derived from their reference to things outside of the words of the sentence, things in the world (e.g. “the tree”, “a car”). Pronouns, on the other hand, derive meaning by referring to other words in the sentence (to R-expressions), or from context, etc. (e.g. “he”, “her”, “they”). Finally, anaphors get their meaning only from R-expressions in the sentence (e.g. “itself”, “ourselves”).
We can find examples of special pronoun and anaphor behavior in these stunningly ungrammatical sentences:
- 1) *Itself bit the dog.
- 2) *He saw John. (where “he” refers to John)
So the question is why are these ungrammatical, and to find that out we need to determine what differences we can find between grammatical and ungrammatical examples.
Coreference
editThe first thing to introduce is a way of indicating whether or not two phrases refer to the same entity in the world. We’ll do this by using a unique subscript letter after the word or phrase for each unique entity.
- 3) [The dog]i bit [the man]j.
- 4) [Bob]i gave [Maria]j [the book]k.
- 5) [John]i thinks that [he]j likes [apple pie]k.
- 6) [Francine]i saw [herself]i in [the mirror]j.
This indexing allows us to note when two phrases refer to the same entity by identifying the same subscript on each phrase. By possessing the same index, that is, by being coindexed, we can determine that they corefer to the same entity.
Secondly, a simple notion of giving meaning is required. We’ll call a phrase an antecedent if it gives meaning to another phrase.
Binding
editWe can now explore some examples of grammatical and ungrammatical sentences to find some initial similarities and differences.
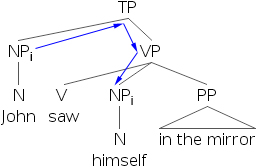
- 7) Johni saw himselfi in the mirror.
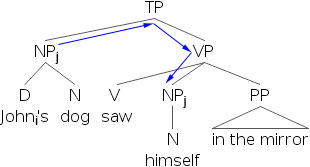
- 8) [Johni’s dog]j saw himselfj in the mirror.
- 9) *[Johni’s dog]j saw himselfi in the mirror.
By examining the structure we find that the anaphor himself can’t corefer with an R-expressing that’s contained within another phrase that’s in subject position. If we examine the tree diagrams below, we’ll find that in the grammatical situations, the antecedents always c-command the anaphor.
- 10)
- 11)
- 12)




 We can now define binding:
- 13) A node X binds a node Y if and only if X c-commands Y, and both X and Y corefer.
In 7-9, the sentence is grammatical only when the anaphor is bound by its antecedent. If this is general, then we should find cases where an anaphor binds its antecent to be ungrammatical.
- 14)


 Since these are all ungrammatical, let’s make a rule out of this.
- 15) Principle A: An anaphor must be bound by its antecedent.
Domains
editIf English were as simple as that we’d be finished with binding, but unfortunately English isn’t that simple. We can easily find examples where an anaphor is bound by its antecedent but the sentence is still ungrammatical.
- 16)
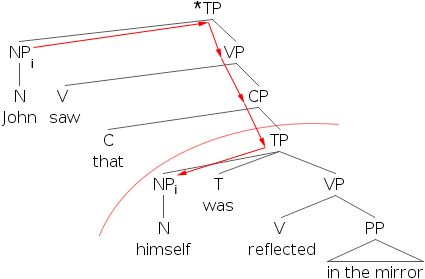

 In order to account for this we have to introduce the concept of a binding domain. Simply, a binding domain is the clause (TP) that contains the anaphor. What we notice about (16), now, is that the antecedent is outside of the binding domain of the anaphor. We can make a revision to Principle A to include a locality constraint (a rule that involves nearness).
- 17) Principle A (v.2): An anaphor must be bound by its antecedent within its binding domain.
For now this theory will suffice, but in the advanced syntax tutorial we’ll look at some easy-to-find examples of binding within a binding domain that still ungrammatical, and we’ll see how we can revise our theory to make it fit better.
Binding Pronouns
editThe behavior of pronouns turns out to be the reverse of anaphors. Consider these sentences:
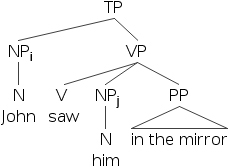
- 18) Johni saw himj in the mirror.
- 19) *Johni saw himi in the mirror.
- 20) Johni saw that hei was reflected in the mirror.
- 21) Johni saw that hej was reflected in the mirror.
- 22)
- 23)

- 24)

- 25)





 In (18), the pronoun is unbound (or free), but in (19) the pronoun is bound. Looking at embedded clauses we find that if the pronoun is in an embedded clause, that is, a different binding domain, then the sentence is grammatical regardless of coreference. In the grammatical cases the pronoun is free within its binding domain, and in the ungrammatical cases it’s bound. We can make a second rule from this.
- 26) Principle B: A pronoun must be free in its binding domain.
Binding R-expressions
editThe last of the set to deal with, after anaphors and pronouns, is R-expressions, the whole set of nouns and phrases that aren’t anaphors nor pronouns. At first it seems like we shouldn’t need to describe where these can go at all, given our previous rules, but we can find perfectly ungrammatical sentences that don’t break either Principle A or B.
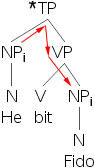
- 27) *Hei bit Fidoi.
- 28) *Bobi saw Franki.
- 29) Hei bit Fidoj.
- 30) Bobi saw Frankj.
- 31)
- 32)

- 33)

- 34)





 In these situations, what we notice is that the sentence is ungrammatical only when the R-expression is bound. We can make a third rule now.
- 35) Principle C: An R-expression must be free.
With binding we now have a fairly complete way to describe many of the behaviors of language, in terms of structure, and we can begin to look at some of the things we can do with this knowledge.
Linguistic Universals
editOne of the biggest concerns of modern linguistics is to discover the fundamental principles that underly all human languages. This will be the motivation for further development of the theories we’ve covered as we’ll see in the advanced syntax tutorial. But even at the level we’re currently working on there are some trends within natural languages that we can explore, which give us insight into things ranging from how cognitive processes formulate sentences to how grammatical features develop over time.
These trends are called Linguistic Universals or Universals of Grammar, and they come in two types: mere statistical trends, and true universals (or “implicational universals”). The statistical trends are just that — trends that appear in patterning that likely come about through historical change under the influence of any number of forces such as ease of cognition. Implication universals, on the other hand, tend to be much more closely followed, and make predictive statements that say if a language has feature X, it’ll almost assuredly have feature Y as well. There are also other ways of dividing universals, namely by the parts of a language that they affect. Phonetic/phonological universals involve the sounds and sound changes that a language goes through, morphological universals involve word structure and morphemes, etc. In this section I’ll be covering the universals that can be related to syntax, and I’ll explore possible ways that these universals can arise from syntax.
Word Order Universals
editWord order typology is the classification of languages by how certain types of words are ordered relative to one another in a sentence or constituent. The most common word order typological classification is the order of subjects, objects, and verbs within a sentence. Since there are three types of words, we have six possible configurations: VSO, SVO, SOV, VOS, OVS, OSV. In surveys of natural languages, the first three, with the subject preceding the object, are overwhelmingly used as the normal declarative word order, the latter three comprising lower single digit percentages. We’ll call these two word orders SO and OS, respectively. For each of the word orders we’ll also identify them by the position of the verb, I, II, and III for verb first, second, and third, respectively. A language can then be classified by a combination of both, as SO/I, OS/III, etc. Because SO word order is so overwhelmingly common, SO word order can simply be assumed on bare verb position numbers (e.g. III would mean SO/III not OS/III, etc.).
A second way of classifying languages is by their use of prepositions or postpositions, which we can call Pr and Po, respectively. A third is the order of adjectives and nouns; if a noun comes before its adjectives we can call this N, if a noun comes after its adjectives we can call this A. Looking at the Pr/Po and A/N classifications in relation to I/II/III classification we can find some interesting trends, such as type I languages always also being Pr, type III languages usually being Po, etc. We can now make a list of possible configurations (ignoring the rare OS configurations) and look at their frequency.
- I-PR-A: Rare
- I-PR-N: Common
- I-PO-A: Rare
- I-PO-N: Rare
- II-PR-A: Common
- II-PR-N: More Common
- II-PO-A: Rare
- II-PO-N: Less Rare
- III-PR-A: Rare
- III-PR-N: Rare
- III-PO-A: More Common
- III-PO-N: Common
Just from this bit of data, and our knowledge of syntax from before, we notice a trend that would be helpful in constructing a believable language. The common forms, I-PR-N, II-PR, and III-PO, all show, by contrast to other forms or by contrast to sub-forms, a preference for keeping consistent head positioning, i.e. languages prefer to be as consistently head-initial or head-final as possible.
Syntactic Universals
editSyntactic universals are more specific than the typical word order universals. They still are visible in the word order of a sentence, but they tend to be much more specialized in scope. For example, question particles in yes/no questions tend to appear after the word they mark, and they tend to appear more in type II and III languages; when they appear in type I languages the particle appears before the word they mark. Auxiliary verbs, too, show interesting syntactic patterning that follows from the generalization about consistent head positioning.
Morphosyntactic Universals
editMorphosyntactic universals are in between syntactic universals and morphological universals in that they involve morphological tendencies in relationship to syntactic features. For example, what we find is that morphological items tend to behave similar to heads in PPs, in that if a language has just suffixing, then it should behave like a language with postpositions and be type III, and indeed this turns out to be the case. Indeed, if a language has just suffixes then it has postpositions, if it has just prefixes then it has prepositions.
In the case of agreement between nouns and adjectives, N languages always have agreeing adjectives. More generally, type III languages almost always have case systems. The full complexity of syntax related tendencies among languages is beyond the scope of this section, but you can read more about them here. Some of the implications that we can derive from these universals would make a nice set of grammatical rules. For instance, the tendency for affixes to behave like adpositions might indicate some hidden structure that involves the affixes as the head of some adposition-like phrase, undergoing some sort of historical change from an adposition to an affix, thus giving us an idea of how to evolve a constructed language. The tendency for languages to try to be consistent in their head positioning could result from a historical process that changes parts of speech into one another. Alternatively, to make a truly alien feeling language, these universals could be reversed, making a Po type I language or something similar. Knowing the universals clearly makes it easier to create both a naturalist language as well as interesting alien languages.
References (linguistic universals)
editGreenberg, Joseph. "Some Universals of Grammar." 1999. 10 Dec 2007 <https://web.archive.org/web/20100531044540/http://angli02.kgw.tu-berlin.de/Korean/Artikel02/>.
Applying this Knowledge to the Conlanging Process
editSo far we’ve explored the beginnings of a syntax as a set of formal theories, but this tutorial is meant to be an aid in constructing a language. To see how we can use this knowledge, I’m going to approach the process of constructing a language from two perspectives. The first is construction from scratch, without any preconceptions or ideas about what the grammar of the language should look like. Then I’ll look at how to take some vague ideas and how to expand them into a full language that you can expect such systems to appear in, and in the process I’ll look at how the same tools can be used to formalize an existing language.
Designing a Syntax from Scratch
editDesign a syntax from scratch is theoretically a simple process. Without any preconceptions about what certain features should look like, we can follow an orderly approach to the process. Indeed, the process is so formulaic that it might even be useful to just write out a list of things to define for the language.
- 1: Head-initial or head-final
- 2: Heads and Phrases (i.e. does the language have Ns? NPs? Vs? VPs? etc.)
- 3: Phrases that are exceptions to (1) or have exceptional alternative forms
- 4: PS rules
Some things to keep in mind, especially in (2) and (4) is that the structures don’t have to be identical to English. Modern theories tend to attempt to describe every language with the same basic formulation, the more in common the better, but that doesn’t mean your language has to. If you want to put the subject into the VP and move the object out of the VP, sure go ahead and do so. But keep in mind that making exceedingly different rules means that your constituency tests should have equivalent forms. If you do indeed move subjects into VP and objects out, you’ll need to have a situation where you can replace the VP with a stand in, something similar to “do so”, and have it mean the same thing. It’s important to keep in mind why we say languages have the rules we’ve found for them, or developed, as the case may be.
Formalizing Ideas and Making Generalizations
editFinding a syntax for preexisting ideas is a bit more complicated than designing one from scratch. Because we already have some “canonical” forms, we have to perform tests on them to discover how they behave. We can perhaps make a list of things to do here to identify the features of the language.
- 1: Constituency tests to decide what composes the structure and how
- 2: PS rules to describe the structure
- 3: Is the structure’s head positioning typical or exceptional?
- 4a: Generalization of 1-3 as guides for the steps to design a syntax from scratch
- 4b: Create more ideas and analyze them
Having multiple ideas would make (3) easier to decide. For example, if we have three ideas that end up having the same head positioning, we might want to say that our language should have that positioning as the typical position. Alternatively, if the ideas have different head positioning we can choose whichever we prefer more and make that typical, while making the other one exceptional.
The rules listed above can apply just as well to a description process as well, treating the entire language as one giant idea to be analyzed. Input from less formal grammars can speed up the process of creating a formal grammar.
Finding Problems with the Current Theory
editThe current theory is very powerful and can account for a great many phenomena in natural languages. Despite this, it still misses an enormous number of sentences that are grammatical, at least in English, and the theory as given can’t account at all for some languages.
English
editEnglish was the language we used to base our current theory on, but within English there are some clear counterexamples to the theory we have. Just within noun phrases we have examples of constituency lower than NP but higher than N. For example, “the big brown dog and the little one too”. In this example “one” replaces “brown dog”, suggesting that the “brown dog” is itself a constituent, but given our existing PS rules for English this shouldn’t be possible. We thus have an anomalous constituent:
- [NP [D the] [AdjP big] [?? [AdjP brown] [N dog]]].
Irish
editIrish is a type SO-I language, which means it has VSO word order. With the above grammar, placing the subject as the daughter of a TP makes it impossible to get it between the verb and the object. If we make new structures between V and VP, like we suggested for English, we’ll still find some example sentences that don’t word. For example, Irish has AuxSVO word order whenever an auxiliary verb is used, which makes it hard to have a single rule to account for word order.
Japanese and Latin
editJapanese and Latin are what are sometimes called non-configurational languages, which means that they don’t have any significant amount of word order on a clause level. Japanese, for instance, only requires that verbs appear at the end of a clause (Japanese is a type III language), and that verb complements appear immediately before the verb. Latin is often cited as an example of a language with no word order on the clause level at all. Non-configurational languages such as these would require a large number of PS rules, one for each possible word order. With large clauses this could get unwieldy very quickly.
In the advanced syntax tutorial we’ll see how modern linguistics approaches these problems, and look at some experimental ways of describing behavior that would be more useful in the conlanging process.