Communication Networks/HTTP Protocol
Hypertext Transfer Protocol (HTTP)
editThe Hypertext Transfer Protocol (HTTP) is an application layer protocol that is used to transmit virtually all files and other data on the World Wide Web, whether they're HTML files, image files, query results, or anything else. Usually, HTTP takes place through TCP/IP sockets.
A browser is an HTTP client because it sends requests to an HTTP server (Web server), which then sends responses back to the client. The standard (and default) port for HTTP servers to listen on is 80, though they can use any port.
HTTP is based on the TCP/IP protocols, and is used commonly on the Internet for transmitting web-pages from servers to browsers.
Network Application:
Client Server Paradigm
The client and server are the end systems also known as Hosts. The Client initiates contact with the server to request for a service. Such as for Web, the client is implemented in the web browser and for e-mail, it is mail reader. And in similar fashion, the Server provides the requested service to client by providing with the web page requested and mail server delivers e-mail.
Peer to Peer Paradigm
In the network, a peer can come anytime and leave the network anytime. So a peer can be a Client or Server. So the Scalability is the advantage in this peer to peer network. Along with Client Server and Peer to Peer Paradigm, it also supports hybrid Peer to Peer and Client Server in real world.
The HTTP protocol also supports one or more application protocols which we use in our day to day life. For e-mails, we use the SMTP protocol, or when we talk to other person on telephone via the web world (Voip). So these applications are through the web world. They define the type of message and the syntax used. Also it gives information on the results or actions taken.
Identifying Applications
When the process of communication has to be performed, there are two main things which are important to know, they are: 1. IP Address: This IP address is of the host running the process. It is an 32 bit address which is unique ID. From this IP address, the host is recognized and used to communicate to the web world. 2. Port Number: The combination of IP address and Port number is called as Socket. Hence , Socket = ( IP address, Port number)
So whenever the client or web user application communicates with the web server, it needs four important components also called as TCP Connection tuple. This tuple consists of: 1. Client IP address 2. Client Port number 3. Source IP address 4. Source Port number
HTTP protocol uses TCP protocol to create an established, reliable connection between the client (e.g. the web browser) and the server (e.g. wikibooks.org). All HTTP commands are in plain text, and almost all HTTP requests are sent using TCP port 80, of course any port can be used. HTTP protocol asks that each request be in IP address form, not DNS format. So if we want to load www.wikibooks.org, we need to first resolve the wikibooks.org IP address from a DNS server, and then send out that request. Let's say (and this is impossible) that the IP address for wikibooks.org is 192.168.1.1. Then, to load this very page, we would create a TCP packet with the following text:
GET 192.168.1.1/wiki/Communication_Systems/HTTP_Protocol HTTP/1.1
The first part of the request, the word "GET", is our HTTP command. The middle part of the request is the URL (Universal Resource Locator) of the page we want to load, and the last part of the request ("HTTP/1.1") tells the server which version of HTTP the request is going to use.
When the server gets the request, it will reply with a status code, that is defined in the HTTP standard. For instance:
HTTP/1.1 200 OK
or the infamous
HTTP/1.1 404 Not Found
The first part of the reply is the version of HTTP being used, the second part of the reply is the error code number, and the last part of the reply is the message in plain, human-readable text.
The Web
editThe web world consists of numerous web pages which consists of objects which are addressed by URL. The web pages mostly consist of HTML pages with a few referenced objects. The URL known as Uniform Resource Locator consists of host name and path name.
The host name is www.sjsu.edu/student/tower.gif
The Web User sends request to the Web Server through agent such as Internet Explorer or Firefox. This User agent handles all the HTTP request to Web server. The same applies to Web Server when it send information to Web User through servers known as Apache server or MS Internet Information Server.
The HTTP is the Web’s application layer protocol works on the Client-Server technology. The client request for the HTML pages towards server and the server responses with HTML pages. In this, the client requests pages and objects through its agent and Server responses them with the requested objects by displaying.
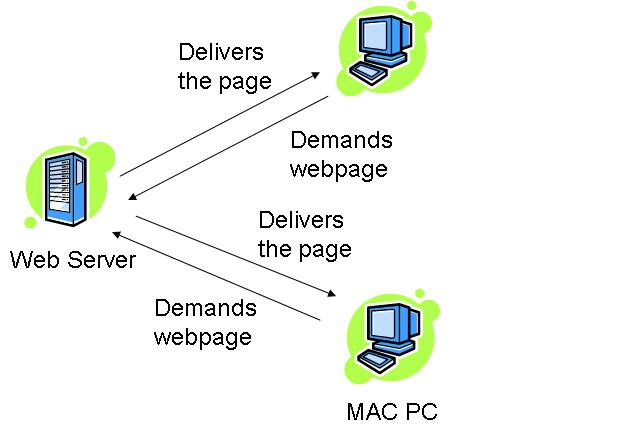

How this works??
The HTTP:TCP transport service uses sockets to transfer the data. The client initiates the TCP connection by using sockets on port 80 to the server. Then the server accepts the connection from the client. The client requests with the HTML pages and the objects which are then exchanged between the client browser and web server. After completing the request, the TCP connection is closed.
As HTTP is a stateless protocol. It does not keep user information about the previous client requests. So, this protocol is simple but if you have to maintain the past client records then it is complex. Since the server will maintain all the client requests and when the server crashes, it is very difficult to get the information back and makes the system very complex.
HTTP Connections
editThe web page consists of objects and URL’s. As there can be one or many objects or URL’s, the type of HTTP connection determines the order in which the objects are requested.
Since the HTTP is constantly evolving to improve its performance, there are two types of connections: • Non-Persistent (HTTP/1.0) • Persistent (HTTP/1.1)
The major difference between non-persistent and persistent connection is the number of TCP connection(s) required for transmitting the objects.
Non-Persistent HTTP – This connection requires that each object be delivered by an individually established TCP connection. Usually there is one round trip time delay for the initial TCP connection. Suppose user requests the page that contains text as well as 5 images. The number of TCP connections will be as follows:


Persistent HTTP -
This connection is also called as HTTP keep-alive, or HTTP Reuse. The idea is to use the same TCP connection to send and receive multiple HTTP requests/responses using the same connection. Using persistent connection is important to improve performance.
Persistent HTTP without Pipelining – In this connection, each client has to wait for the previously requested object received before issuing a new request for another object. Thus, not counting the initial TCP establishment (one RTT time), each object needs at least one RTT plus the transmission time of the object by the server.
Persistent HTTP with Pipelining – Can allow client to send out all (multiple) requests, so servers can receive all requests at once, and then sending responses (objects) one after another. The Pipelining method in HTTP/1.1 is default. The shortest time in pipelining is one initial RTT, RTT for request and response and the transmission time of all the objects by the server.
Thus, we can say that the number of RTT’s required in all the above types considering for some text and three objects would be:
- Non-persistent HTTP:
- Persistent HTTP
- Without Pipelining:
- With Pipelining:
Response Time (Modeling)
editRound Trip Time (RTT): The time taken to send a packet to remote host and receive a response: used to measure delay on the network at a given time.
Response time:
The response time denotes the time required to initiate the TCP connection and the next response and requests to receive back along with the file transmission time.
The following example denotes the response time -


From the above fig. we can state that the response time is :
2 RTT + File transmit time.
HTTP Message Format :
editThere are two types of messages that HTTP uses – 1. Request message 2. Response message
1. Request Message:
editThe request line has three parts, separated by spaces: a method name, the local path of the requested resource and version of HTTP being used. The message format is in ASCII so that it can be read by the humans.
For e.g.:
GET /path/to/the/file.html HTTP/1.0
The GET method is the most commonly used. It states that “give me this resource”. The part of the URL is also called as Request URL. The HTTP is to be in uppercase and the next part denotes the version of HTTP.
HTTP Request Message: General Format
The HTTP Request message format is shown below:
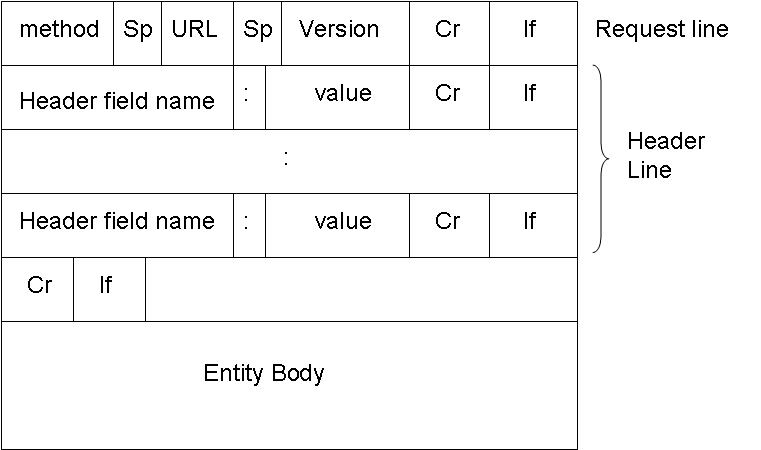

The method is the type of method used to request the URL. Like GET, POST or HEAD. The URL block contains the requested URL. Version denotes the HTTP version. Either HTTP/1.0 or HTTP/1.1. The header lines include the browser type, host , number of objects and file name and the type of language in the requested page. For e.g.:


The entity body is used by the POST method. When user enters information on to the page, the entity body contains that information.
The HTTP 1.0 has GET, POST and HEAD methods. While the HTTP 1.1 has along with GET, POST and HEAD, PUT and DELETE.
Uploading the information in Web pages
The POST method
The Web pages which ask for input from user uses the POST method. The information filled by the web user is uploaded in server’s entity body.
The typical form submission in POST method. The content type is usually the application/x-www-form-urlencoded and the content-length is the length of the URL encoded form data.
The URL method
The URL method uses the GET method to get user input from the user. It appends the user information to be uploaded to server to the URL field.
2. Response Message:
editThe HTTP message response line also has three parts separated by spaces: the HTTP version, a response status code giving result of the request and English phrase of the status code. This first line is also called as Status line.
The HTTP Response message format is shown below:
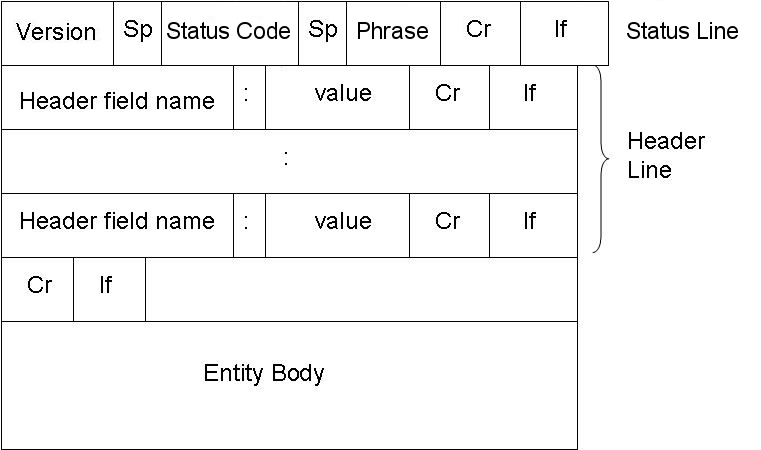

E.g.:
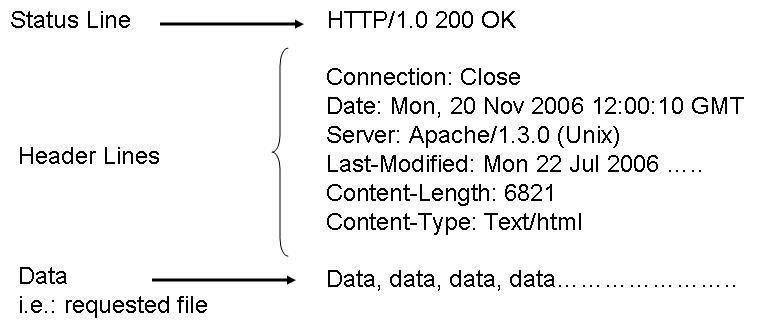

Below are the some HTTP response status codes:
200 OK The request succeeded, and the resulting resource (e.g. file or script output) is returned in the message body.
404 Not Found The requested resource doesn't exist.
301 Moved Permanently
302 Moved Temporarily
303 See Other (HTTP 1.1 only)
The resource has moved to another URL (given by the Location: response header), and should be automatically retrieved by the client. This is often used by a CGI script to redirect the browser to an existing file.
500 Server Error
An unexpected server error. The most common cause is a server-side script that has bad syntax, fails, or otherwise can't run correctly.
User Server Identification
editThe HTTP Protocol is a stateless protocol. So there should be an mechanism to identify the user using the web server. There are various techniques used:
1. Authentication 2. Cookies
1. Authentication:
The Client whenever request for the web page from the web server, the server authenticates the user. So each time whenever the web user or client requests any object, it has to provide a name and password to be identified by server. The need arises for the authentication so that the server has control over the documents. And, Since the HTTP protocol is stateless, it has to provide information each time it requests for web page. The authorization is done at the header line of the request. Generally, the cache is used to store the name and password of the web user. So that, each time it doesn’t have to provide the same information.
2. Cookies
Cookies are used by web servers to identify the web user. They are small piece of data stored into the web users disk. It is used in all major websites. As they have relatively much more importance in the web world. As said earlier, cookie is a small piece of data and not a code. This piece of small information is stored into web users machine whenever the browser visits the server site’s.
So how do the Cookie function exactly?
When the web users browser requests a file from web server, it send the file along with a cookie. So the next time whenever the web browser requests the same server a file, it sends the previous cookie to the web server so that it identifies that the browser had previously requested for a file. And so the web server coordinates your access to different pages from its website.
A typical example can be when you do online shopping., where cookie is used to traced your shopping basket .
The major four component of Cookie are:
1. Cookie header line in the HTTP response message. 2. Cookie header line in the HTTP request message. 3. Cookie file stored in User’s host and managed by User’s browser. 4. Back end database at the web site. So we can say that Cookies are used to keep the State of the web browser. Since HTTP is a stateless, so there should be some means for server to remember the state of the client’s request.
Cookies are in two flavors, one is persistent and the other is non-persistent. Persistent Cookies remain in the web browser’s machine memory for the specified time when it was first created. While non-persistent cookies are the ones which are deleted as soon as the web user’s browser is closed.
Cookies bring a number of useful applications in today’s Internet world. With the help of cookie, you can have: • User accounts • Online Shopping • Web Portals • Advertising
But with these cookies, you can secretly track down the web user’s habits. As whenever a web browser sends a request to web server, it includes its IP address, the type of browser you use and your operating system. So this information is also logged into the server’s file.
The Advertising is the main issue in cookies. Since, it is less admirable because of its use as a tracking of individual’s browsing and buying habits. As the server’s log file has all your information, so it becomes easier to track you. The advertisement firm has many clients which includes another several advertising firms. So it has contracts with many other agencies. They place an image file on their web site. Once you click on them, you are not clicking on the image but a link to another advertising firm’s site. So it sends a cookie to you when you request for that page. And thus, your IP address is tracked down. Whenever you request to their site’s page, they can track your number of visits to their site, which page you have visited and how often. Therefore, they come to know about your interests. So this important piece of information is valuable to them to track your preferences and target you based on your inferences.
Web Caching (Proxy Server)
editThe proxy server’s main goal is to satisfy client’s request without involving the original web server. It is a server acting like as a buffer between the Client’s web browser and the Web server. It accepts the requests from the user and responses to them if it contains the requested page. If it doesn’t have the requested page, then it requests to Original Web Server and responses to the client. It uses cache to store the pages. If the requested web page is in cache, it fulfills the request speedily.
Working of Proxy Server


The two main purpose of proxy server are:
1. Improve Performance –
As it saves the result for a particular period of time. If the same result is requested again and if it is present in the cache of proxy server then the request can be fulfilled in less time. So it drastically improves the performance. The major online searches do have an array of proxy servers to serve for a large number of web users.
2. Filter Requests -
Proxy server’s can also be used to filter requests. Suppose an company wants to restrict the user from accessing a specific set of sites, it can be done with the help of proxy servers.
Conditional GET
The conditional GET is the same as GET method. It only differs by including the If-modified-since, If-unmodified-since, If-match, If-None-Match or If-Range header field. The conditional GET method requests can be satisfied under the given conditions. This is method is used to reduce the network usage so that cache entities can be utilized to fulfill requests if they are not modified and avoids unnecessary transferring of data.
Working of Conditional GET:
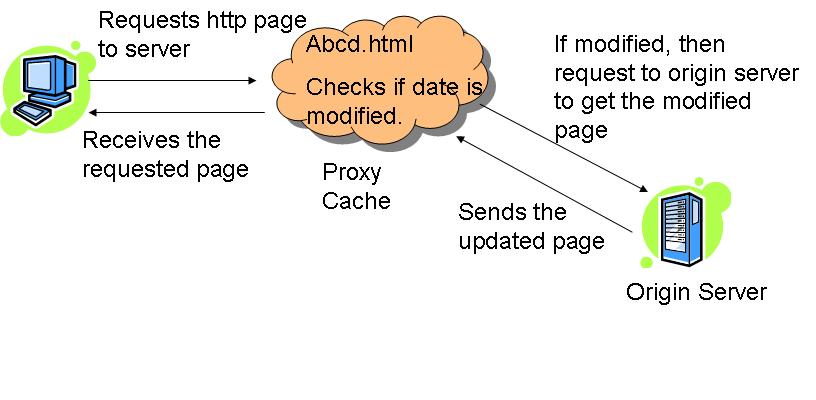

Whenever the client request to the server for html page, the proxy server checks the requested page in its cache. It checks the last-modified date entry in the header


If the requested page in the cache entry determined to be out of date, the proxy server requests the updated page from the main server. And then, the main server responds to that requests and sends updates to the page to the proxy server; which are then forwarded to the client, as well as stored in the proxy server cache.
HTTPS
editThe HTTPS is a secure version of HTTP. It indicates the port 443 should be used instead of port 80. It is widely used, both in security concern areas such as eCommerce, as well as crime prevention by attempting to make sure the end user is actually getting the sites he was looking for. The protocol identifier HTTPS instructs the user agent the user is looking for a secure channel.
The HTTPS follows a procedure to follow secure connection in the network. The secure connection is done automatically. The steps are:
- The client authenticates the server using the server’s digital certificate.
- The client and server negotiate with the cipher suite (a set of security protocols) they will use for the connection.
- The client and server generate session keys for encrypting and decrypting data.
- The Client and server establish a secure encrypted connection.
The HTTPS ends its session whenever the client or server cannot negotiate with the cipher suite. The cipher suite can be based on any of the following:
- Digest Based –
- Message Digest 5 (MD5)
- Secure Hash Algorithm 1 (SHA-1)
- Public Key-Based –
- Rivest-Shamir-Adelman (RSA) encryption/decryption.
- Digital Signature Algorithm (DSA)
- Diffie-Hellman Key-exchange/Key-generation.
- X.509 digital certificates.
SUMMARY
editThis chapter includes HTTP how the Web World is all about. The various methods used in TCP connection to transfer the data in the web world. It has detail information on requests and response methods. Also it contains the User Identification methods like Authentication and Cookies. The cookies part is explained in detail. Also the various connections in HTTP, like non-persistent and persistent connections. We have also mentioned about the proxy server and how does it works. And lastly, the secure version of HTTP.i.e. HTTPS.